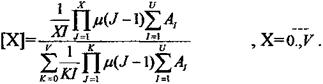|
Рефератырусскому языку полиграфия хозяйство |
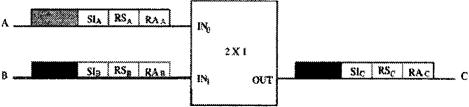
Дипломная работа: Коммутация в сетях с использованием асинхронного метода переноса и доставки3.5.3 ДВОЙНАЯ СИСТЕМА С ПЕРЕСТАНОВКОЙ И ИСПРАВЛЕНИЕ ОШИБОК МАРШРУТИЗАЦИИSN система с исправлением ошибок очень эффективна, особенно при большом значении п. Так как, при каждом отклонении ячейки, ее трассировка должна начинаться снова [20]. Рассмотрим диаграмму состояний на рисунке 3.16.
Рисунок 3.16 - Фазовая диаграмма ячейки в SN сети Состояние (положение) - это расстояние или число каскадов до вывода. Требуемая сеть должна быть такой, как показано на рис. 3.17, в которой штраф - это возврат только на один каскад [18,14].
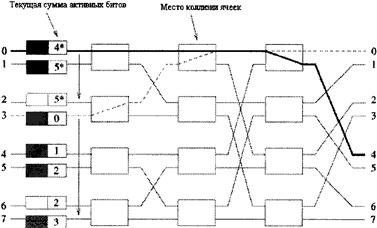
Рисунок 3.17 - Фазовая диаграмма со штрафным состоянием На рисунке 3.18 изображена коммутационная система 8x8 без перестановки (USN). Она является зеркальным отражением системы SN. Трассировка через последовательность каскадов основана на принципе наименее значимый бит через наиболее значимый бит
Рисунок 3.18 - Коммутационная система без перестановки с пятью Каскадами Пользуясь той же схемой вычислений, как в случае с SN, канал ячейки с адресом источника S=s1...sn и адресом назначения D=d1...dn может быть выражен так[18,14]:
(n-1) разрядное окно, перемещающееся по двоичной цепи d2...dn, s1...sn-1 на один бит каждый каскад справа на лево, представляет последовательность узлов на канале трассировки. Первоначальное состояние ячейки (d1...dn, s1...sn-1) и состояние перехода дано как:
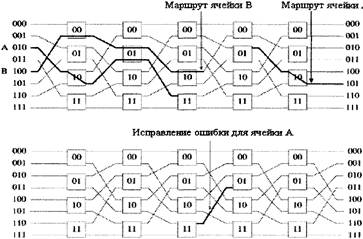
На последнем каскаде ячейка находится в состоянии (-d1d2...dn) и достигает назначения [18]. Предположим, что USN наложена на SN и каждый узел USN соединен с соответствующим узлом SN, так, что ячейка из любого ввода может попасть в любой вывод узла. Взаимосвязи с перестановкой и без перестановки между соседними каскадами компенсируют друг друга, таким образом, что ошибка, вызванная отклонением ячейки в SN, может быть исправлена в USN возвратом только на один шаг. Рассмотрим рисунок 3.19.
Рисунок 3.19 - Исправление ошибок в сетях SN с помощью USN
Рисунок 3.20 На рисунке 3.20 ячейка А поступает в SN из входа 010 и выходит из вывода 101, ячейка В поступает во ввод 100 и выходит через вывод 100. Во втором каскаде они сталкиваются, когда обе прибывают в узел 01 и делают запрос выводу 0. Допустим, что ячейка В выигрывает, а ячейка А отклоняется и попадает в 11 узел третьего каскада. Допустим, что ячейка А попадает в аналогичный 11 узел в USN и коммутируется в вывод 0. Затем она возвращается в узел 01, тот самый узел, где произошла ошибка в двух каскадах. В этом месте ошибка отклонения была исправлена и ячейка А продолжила свой путь по нужному каналу в SN. Любая ошибка трассировки исправляется в SN обратной операцией трассировки в USN. Более точно этот процесс можно сформулировать так. Рассмотрим ячейку в состоянии (r1…rk, x1…xn-1) Ячейка должна быть трассирована в канал <rk, x1> в SN. Положим, она отклонилась, вместо того, чтобы попасть в канал <rk, x1> ячейка достигает узла (x2.....хn-1rk) в следующем каскаде. Исправление ошибки трассировки начинается с присоединения бита x1 к ярлыку трассировки, вместо перемещения бита rk, таким образом, состояние ячейки в следующем каскаде будет x1. Затем ячейка перемещается в аналогичный узел в USN для исправления ошибки. В случае успешной трассировки, она будет направлена в канал rk и вернется в предыдущее состояние (r1…rk x1, x2…xn-1 rk). Taким же образом, ошибка, происходящая в USN исправляется с помощью SN за один шаг. Т.е. ячейка в SN может отклониться в канал USN и наоборот [14,20].
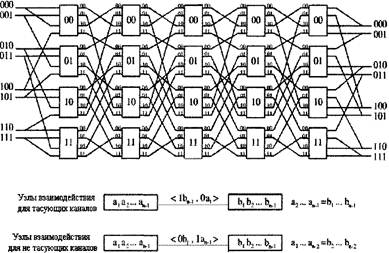
Рисунок 3.21- Двойная коммутационная система 8x8 с перестановкой Это учитывается в следующем алгоритме. Сначала 2´2 аналогичных коммутационных элемента SN и USN объединяются и образуют 4x4 коммутационных элемента для того, чтобы можно было коммутировать ячейки между SN и USN. На рисунке 3.21 представлена двойная SN, образованная 4´4 коммутационными элементами. Используется новая схема маркирования. Четыре ввода/вывода коммутационного узла помечаются 00, 01, 10, 11 сверху вниз. Выходы 00 и 01 соединяются со следующим каскадом по примеру USN, а выводы 10 и 11 соединяются со следующим каскадом по примеру SN. Вводы 00 и 01 соединяются с предыдущим каскадом по SN образцу, а вводы 10 и 11 соединяются с предыдущим каскадом по образцу USN. Канал с меткой <la,0b> - это не тасующий канал, а канал с меткой <0a,1b> - тасующий. Два узла (a1, an-1) И (bi, bn-1) соединены не тасующим каналом, если <0b1, 1an-1> и они соединены тасующим каналом, если a1...an-2 = b2...bn-1 Так как каждый коммутационный узел имеет четыре вывода, то для определения требуемого вывода ячейки на каждом каскаде, необходимо два бита маршрутизации. Ячейка с назначением D=d1...dn может трассироваться как через USN, так и через SN. Соответственно, изначальный ярлык маршрутизации ячейки установлен на 0d1…0dn (USN) или на 1dn...1d1 (SN) Состояние ячейки в определенные временные интервалы обозначается (c1r1..ckrkx1…xn-1) Возможны две регулярные передачи в коммутационный узел. Ячейка будет отправлена в не тасующий канал, если ck=0 и в тасующий, если ck=1 [14,19]. Соответственные состояния передачи выражаются:
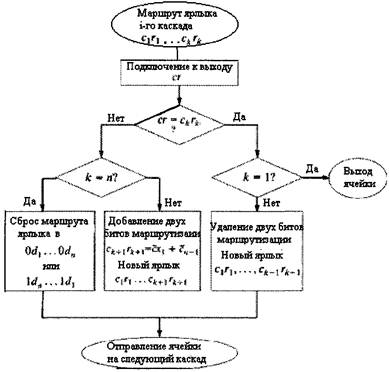
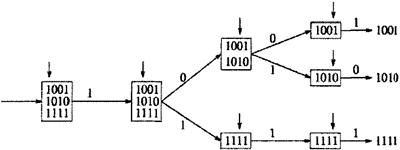
Ячейки с начальной трассировкой, установленной на 0d1…0dn (1dn …1d1) будут оставаться в каналах USN (SN) в течение всего процесса трассировки, пока он не завершится в одном из каналов USN(SN). Направление трассировки: 1. Если вывод ckrk доступен и k=1, ячейка доходит по назначению. Выводим ячейку перед следующем перемешиванием, если с=1 и после следующей не тасовки, если с=0. 2. Если вывод ckrk доступен и k>l, удаляем два наименее значимых бита из ярлыка трассировки и отправляем ячейку в следующий каскад. 3. Если вывод ckrk недоступен и k<n выбираем любой другой доступный вывод, присоединяем к ярлыку трассировки два соответствующих бита для исправления ошибок и отправляем ячейку в следующий каскад. Если вывод ckrk недоступен и k=n устанавливаем исходное значение ярлыка трассировки 0d1…0dn (1dn …1d1), чтобы предотвратить рост длины ярлыка. На рисунке 3.22 представлен полный алгоритм для исправления ошибок [14].
Рисунок 3.22 - Полный алгоритм исправления ошибок Для любого узла с меткой (x1...xn-1) ярлык
исправления ошибок выводов 00 и 01 xn-1 и выводов 10 и 11 0х. В
обоих случаях ярлык исправления ошибок - второй компонент
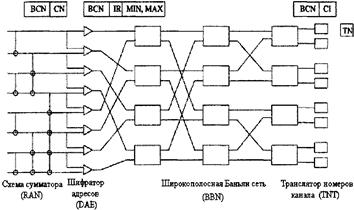
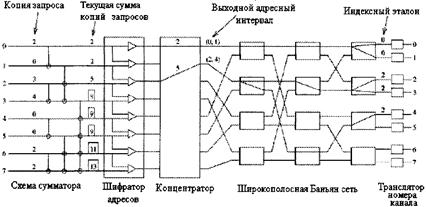
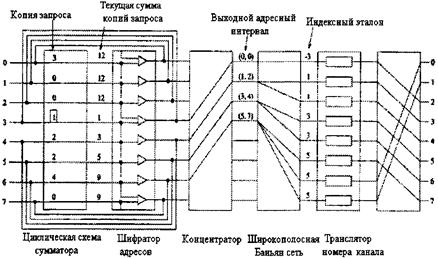
Рисунок 3.23- Пример исправления ошибок трассировки в DSN 3.5.4 КОПИРУЮЩИЕ СИСТЕМЫ ДЛЯ МНОГОАДРЕСНОЙ ПЕРЕДАЧИНа рисунке 3.24 показана серийная комбинация копирующей сети и двухточечного коммутатора для обеспечения многоточечной связи. Копирующая система одновременно тиражирует ячейки из разных вводов и затем трассирует копии ячеек широкой рассылки по их назначению с помощью двухточечного коммутатора [12,14]. Копирующая система состоит из следующих основных частей (рисунок 3.25) [14]: 1. схема сумматора (RAN), генерирующая текущие суммы номеров копий, обозначенных в заголовках входящих ячеек. 2. шифратор адресов (DAE), создающий новые заголовки ячеек из соседних текущих сумм. 3. коммутационная широкополосная Баньян сеть (BBN), в которой коммутационные узлы широкой рассылки делают копии ячеек с заголовками в два бита.
Рисунок 3.24 - Коммутатор многоадресной рассылки 4. шифратор адресов (DAE), создающий новые заголовки ячеек из соседних текущих сумм. 5. коммутационная широкополосная Баньян сеть (BBN), в которой коммутационные узлы широкой рассылки делают копии ячеек с заголовками в два бита. 6. транслятор номеров каналов (TNT), определяющий номера выходных каналов для каждой копии ячейки.
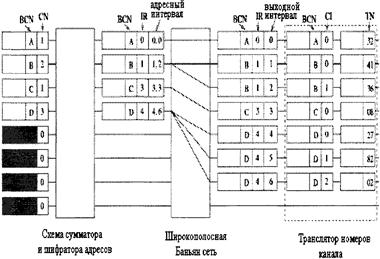
Рисунок 3.25 - Основные компоненты не блокирующей копирующей системы Механизм многоадресной передачи копирующей системы основан на передаче и преобразовании заголовков (рисунок 3.26). Номера копий (CN), указанные в заголовках ячеек рекурсивно суммируются в схеме сумматора. На основе полученных сумм шифраторы адресов создают новые заголовки ячеек с двумя полями: поле фиктивного адресного интервала и поле индексного эталона (IR). Поле адресного интервала образовано соседними текущими суммами, минимальными (MIN) и максимальными (МАХ). Индексный эталон приравнивается минимуму адресного интервала и впоследствии используется транслятором номеров каналов для определения индекса копии (СI).Широкополосная Баньян сеть копирует ячейки по алгоритму логического деления интервалов на основе адресного интервала в новом заголовке. Когда копия прибывает в нужный вывод, TNT вычисляет ее CI на основе адреса вывода и индексного эталона. Номер канала широкой рассылки (BCN) и CI образуют уникальный идентификатор, указывающий на номер канала (TN), который добавляется заголовку ячейки и используется для ее трассировки по назначению [14,20].
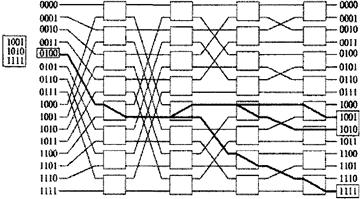
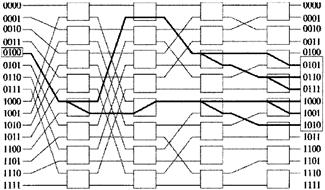
Рисунок 3.26 - Трансляция заголовков в копирующей системе 4 ШИРОКОПОЛОСНАЯ БАНЬЯН СЕТЬ 4.1 ОСНОВЫ ШИРОКОПОЛОСНАЯ БАНЬЯН СЕТЬ4.1.1 ОБОБЩЕННЫЙ АЛГОРИТМ САМОТРАССИРОВКИШирокополосная Баньян сеть - это сеть с коммутационными узлами, копирующими ячейки. Ячейка, прибывающая в каждый узел, может быть либо трассирована в один из выводных каналов, либо дублирована и отправлена по двум выводным каналам. Существует три варианта Log23=1.585, а это значит, что минимальный объем информации заголовка = 2 бит а каждый узел [1,10]. На рисунке 4.1 представлен обобщенный алгоритм одно - битовой самотрассировки для ряда N-битных адресов с произвольным назначением. Когда ячейки прибывает в узел k-каскада, трассировка ячейки определяется k битами заголовков всех адресов назначения. Если все они равны 0 или 1, тогда ячейка отправляется в выводы 0 или 1 соответственно. В противном случае, копии ячеек отправляются в оба вывода, и соответственно копиям этих двух ячеек в заголовках изменяются адреса назначения: заголовки копий ячеек, отправленных в вывод 0 или 1, содержат адреса первоначальных заголовков в k бит, равных 1 или 0 соответственно.
Рисунок 4.1 - Обобщенный алгоритм самомаршрутизации На рисунке 4.2 дерево ввода-вывода, образуемое обобщающим алгоритмом самомаршрутизации.
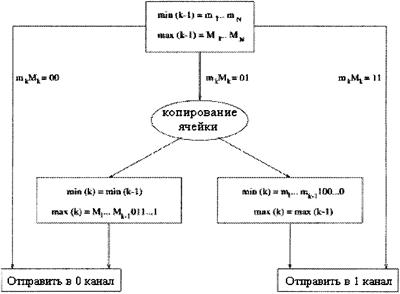
Рисунок 4.2 - Дерево ввода-вывода, образуемое обобщающим алгоритмом самомаршутизации При выполнении обобщенного алгоритма самотрассировки могут возникнуть трудности [12,18]. o заголовки ячеек содержат изменяющиеся адресные номера и коммутационным узлам приходится считывать их все. o при модификации заголовков ячеек учитывается вся совокупность адресов, что усложняет работу коммутационных узлов. o схема всех каналов выводов и вводов образует дерево в сети. Деревья, образованные произвольным рядом входных ячеек, зависят от каналов. Таким образом, из-за нерегулярности ряда абсолютных адресов назначения в заголовках ячеек, система является блокирующей. Но в копирующей системе, где ячейки копируются, но не отправляются по абсолютным адресам, вместо абсолютных адресов могут использоваться фиктивные. Фиктивные адреса каждой ячейки могут выстраиваться непрерывно, так чтобы весь ряд фиктивных адресов представлял интервал (адресный), состоящий из MIN и МАХ текущих сумм. Адресный интервал входных ячеек можно сделать монотонным для обеспечения деблокирования в нижеописанной широкополосной Баньян сети. 4.1.2 АЛГОРИТМ ЛОГИЧЕСКОГО ДЕЛЕНИЯ ИНТЕРВАЛОВАдресный интервал - это непрерывный ряд двоичных N-битных номеров, которые можно представить двумя номерами: минимальным и максимальным. Допустим, что узел в k каскаде получает ячейку, заголовок которой содержит адресный интервал, состоящий из двух бинарных номеров min(k-1)=m1...mN и max(k-1)=M1...MN, где k-1 обозначает каскад, из которого ячейка прибыла в k каскад. По обобщенному алгоритму самотрассировки маршрут ячейки определяется так (рисунок 4.3) [14]: 1. если mk=Мk=0 или mk=Мk=1, тогда отправьте ячейку в выводы 0 или 1 соответственно. 2. Если mk=0 и Мk=1, тогда копируйте ячейку, модифицируйте заголовки обеих копий (по ниже данной схеме) и отправьте копии в соответствующий канал.
Рисунок 4.3 - Логическая схема коммутационного узла в k каскаде широкополосной Баньян сети Модификация заголовка ячейки заключается в делении исходного адресного интервала на два подинтервала, что выражается в следующей рекурсии: для ячейки, отправленной в канал 0 min(k)=min (k-1)=sm1...mN, max(k)=M1.....Mk-101....1, И для ячейки, отправленной в канал 1 min(k)=m1....mk-1 10....0, max(k)=max(k-1)=M1.....МN На рисунке 4.4 (а) представлена схема алгоритма логического деления интервалов. Из правил ясно, что mi=Mi, i=1...k-1 действительно для каждой прибывающей в каскад k ячейки. Событие mk=1 и Mk=0 исключено.
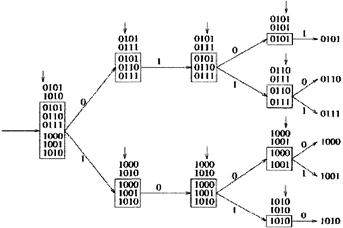
Рисунок 4.4 (а) - Схема алгоритма логического деления интервалов На рисунке 4.4 (b) представлено дерево, которое образуется при копировании ячеек в соответствии с их адресными интервалами [12,14].
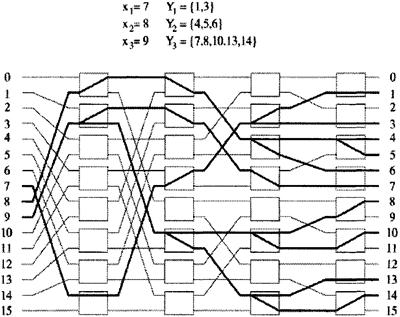
Рисунок 4.4 (b) - Дерево, образованное при копировании ячеек в соответствии с их адресными интервалами 4.1.3 УСЛОВИЯ НЕ БЛОКИРОВАНИЯ В ШИРОКОПОЛОСНЫХ БАНЬЯН СЕТЯХШирокополосная Баньян сеть является не блокирующей, если активные входы х1…xk и соответствующие выходы Y1...Yk соответствуют следующим требованиям [13,18]: - Монотонность Y1<Y2 <....<Yk или Y1>Y2>...>Yk - Концентрация: любой ввод между двумя активными вводами так же является активным. Неравенство Yi<YJ означает, что каждый адрес выхода в YJ меньше адреса выхода в YJ. На рисунке 4.5 дан пример неблокирования с активными вводами x1=7, х2=8, х3=9 и соответствующими выходами Y1={1,3}, Y1= {4,5,6}, Y3={7,8,10,13,14}.
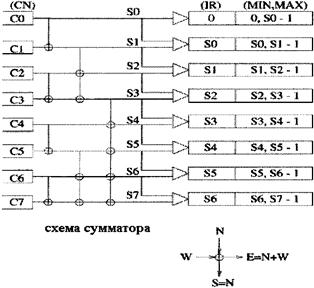
Рисунок 4.5 - Условия не блокирования в широкополосной Баньян сети 4.1.4 ПРОЦЕСС КОДИРОВАНИЯСхема сумматора (RAN), совместно с шифратором адресов (DAE), используется для организации адресов назначения каждой ячейки таким образом, чтобы каждая существенная ячейка была копирована без конфликтов в широкопосной Баньян сети. В ней проходят два процесса копирования ячеек: процесс кодирования и процесс декодирования. В процессе кодирования осуществляется преобразование рядов номеров копий, указанных в заголовках входящих ячеек, в ряд монотонных адресных интервалов, образующих заголовки ячеек в широполосной Баньян сети. Этот процесс осуществляется схемой сумматора и рядом шифраторов фиктивных номеров. От процесса декодирования зависит адрес назначения копий с транслятора номеров канала (TNT) [12,14]. Рекурсивная структура log2N схемы сумматора показана на рисунке 4.6.
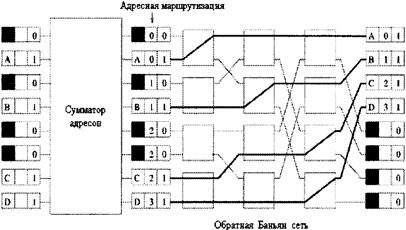
Рисунок 4.6 - Схема сумматора и шифратора фиктивных адресов Схема сумматора состоит из (N/2)log2N сумматоров, каждый с двумя вводами и выводами. Вертикальная линия обозначает пересылку. Восточный ввод равен сумме западного и северного вводов, а южный вывод продолжает северный ввод. Текущие суммы CN генерируются у каждого порта в конце log2N каскадов, а затем шифраторы фиктивных адресов образуют новые заголовки из соседних текущих сумм. Новый заголовок содержит два поля: интервал фиктивных адресов, представленный двумя 1оg2N-битовыми двоичными номерами (минимальным и максимальным). Другое поле содержит индексный эталон, равный минимуму адресного интервала. Заметьте, что длина каждого интервала равна соответствующему номеру копии в обоих адресных схемах. Примем за Si i-текущую сумму. Тогда последовательность интервалов фиктивных адресов производится так [18]: (0,S0-1),(S0,S1)……..(SN-2,SN-1-1) где адрес размещается, начиная с 0. Эта последовательность обеспечивает деблокирование в баньян сети широкой рассылки. 4.1.5 КОНЦЕНТРАЦИЯДля того, чтобы широкополосная Баньян сеть была не блокирующей, необходимо сократить число свободных вводов, находящимися между активными вводами. Это должно быть сделано до ввода ячеек в сеть, т.е. до RAN или сразу же после DAE. Так обратная Баньян сеть используется для концентрации активных вводов в непрерывный список [11,13]. Для получения ряда непрерывных монотонных адресов в обратной Баньян сети трассировочный адрес определяется текущими суммами на бит активности, (рисунок 4.6).
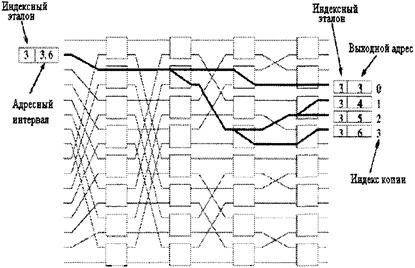
Рисунок 4.7 - Входной концентратор состоящий из сумматора адресов и обратной Баньян сети 4.1.6 ПРОЦЕСС ДЕКОДИРОВАНИЯКогда ячейка выходит из баньян сети широкой рассылки, адресный интервал в ее заголовке содержит только один адрес, т.е. по алгоритму логического разделения интервалов[13]: min(log2N)=max(log2N)=Выходному адресу Копии ячеек, из одного и того же канала широкой рассылки отмечаются CI, который определяется на выходе широкополосной Баньян сети следующим образом (рисунок 4.7): СI=Выходной адрес-индексный эталон
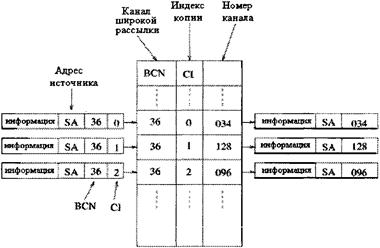
Рисунок 4.7 - Вычисление индексов копий Индексный эталон изначально приравнивается минимуму адресного интервала. TNT (транслятор номера канала) присваивает абсолютный адрес каждой копии ячейки, и она трассируется к своему конечному назначению в последующий двухточечный коммутатор. Присвоение TN (номера канала) завершается простым табличным поиском, при котором идентификатор состоит из BCN (канала широкой рассылки) и CI (индекса копии), связанными с каждой ячейкой. Когда TNT (транслятор номера канала) получает копию ячейки, сначала он преобразует выходной адрес и IR (индексный эталон) в CI (индекс копии), а затем заменяет BCN (канал широкой рассылки) и CI (индекс копии) соответствующими TN (номерами каналов) в таблице перевода [14]. Процесс пересчета иллюстрирован на рисунке 4.8.
Рисунок 4.8 - Пересчет номера канала с помощью табличного поиска 4.2 ПЕРЕПОЛНЕНИЕ И РАЗДЕЛЕНИЕ ВЫЗОВАВ RAN (схеме сумматоров) копирующей системы происходит перегрузка, в том случае, когда число запросов копий превышает пропускную способность копирующей системы. Если частичное обслуживание (которое так же называется разделением вызова) невозможно при копировании ячейки, и ячейка должна произвести все свои копии за один временной интервал, тогда в случае переполнения пропускная способность может снижаться. На рисунке 4.9 показано переполнение, которое произошло у 3-го порта, и пропускаются только пять копий ячеек, при наличии более восьми запросов [14].
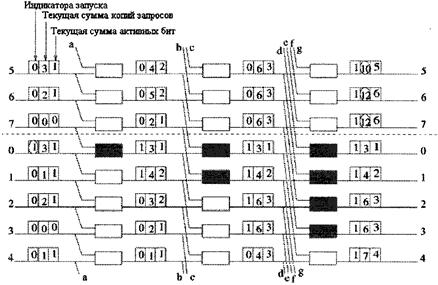
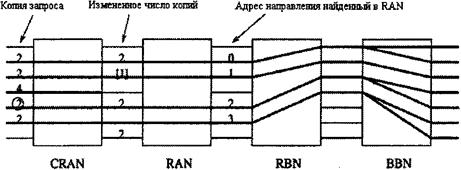
Рисунок 4.9 - Не блокирующая копирующая система 8´8 без разделения вызовов 4.2.1 ПЕРЕПОЛНЕНИЕ И РАВНОДОСТУПНОСТЬ ВВОДОВПереполнение также делает входящие ячейки неравноправными, так как начало работы RAN (схема сумматоров) фиксирована. Поскольку вычисление текущей суммы начинается всегда с 0-го входного порта каждый временной интервал, входные порты с малыми номерами имеют высший приоритет обслуживания, чем входные порты с большими номерами. С этой трудностью можно справиться, если разработать RAN таким образом, чтобы подсчитывать текущие суммы циклично, начиная с любого входного порта. Начало вычисления текущих сумм каждый промежуток времени адаптивно определяется состоянием переполнения в предыдущий промежуток времени. Такая цикличная RAN (CRAN) показана на рисунок 4.10. Текущий исходный пункт - порт 3, разделение вызова происходит у порта 6, поэтому в следующий временной интервал исходным пунктом будет порт 6. Отрицательный индексный эталон -3, данный DAE, значит, что запрос копии из порта 3 является остаточным, и в предыдущий временной интервал были созданы три копии [18,19].
Рисунок 4.10 - Циклическая схема сумматоров (CRAN) в копирующей системе 8´8 4.2.2 ЦИКЛИЧЕСКАЯ СХЕМА СУММАТОРА (CRAN)На рисунке 4.10 показано строение 8´8 CRAN. Ассоциированный формат заголовка ячейки состоит из трех полей: 1 - поля индикатора запуска (SI), 2 - текущая сумма (RS), 3 - адрес трассировки (RA). Только один порт, являющийся исходным пунктом, изначально имеет SI, отличный от нуля. RS поле первоначально устанавливается в число копий, запрашиваемых входной ячейкой [11,14]. Поле RA первоначально устанавливается в 1, если порт является активным. Если порт свободен, оно устанавливается в 0. На выходе RAN поле RA переносит текущую сумм на биты активности, чтобы использовать ее в качестве адреса трассировки в следующем концентраторе. В каждом каскаде CRAN используется ряд цикличных трактов, и таким образом, рекурсивное вычисление текущих сумм может производиться циклично. Для эмуляции вычисления фактической текущей суммы из исходного пункта, некоторые тракты должны быть удалены, как показано на рисунке 4.10.
Рисунок 4.10- Циклическая RAN 8´8 Это равносильно тому, как если, имея теневые (вспомогательные) узлы, не учитывать их каналы при вычислении текущих сумм. Эти узлы следуют за заголовком ячейки с поле SI, равным 1, во время передачи его через CRAN из исходного пункта. Модификация заголовка представлена на рисунке 4.11. Следующий исходный пункт останется неизменным, если не произойдет переполнения. В этом случае первый порт, в котором произойдет переполнение, будет исходным пунктом. Если мы примем за исходный пункт порт 0, а остальные порты циклически пронумеруем от 1 до N-1, тогда SI бит, обозначающий следующий исходный пункт, будет обновлен вместе с соседними RS полями так:
и
где i=1, 2...N-l. Для разделения вызова каждый входной порт должен знать, сколько получено копий за временной интервал. Эта информация называется начальным числом копий (SCN).
Рисунок 4.11 - Операции в CRAN узле Затем устанавливается ряд цепей обратной связи для возвращения этой информации во вводные порты. SCN и соседние текущие суммы вычисляются так SCN0=RS0, и
4.2.3 КОНЦЕНТРАЦИЯИсходным пунктом в CRAN не обязательно является вывод 0 и получившаяся в итоге последовательность адресов трассировки в RBN может быть непрерывно монотонной. В RBN могут происходить столкновения, как показано на рисунке 4.12. Эта проблема разрешима, если к RBN присоединить дополнительный RAN с фиксированным исходным пунктом 0. Дополнительный RAN пересчитывает текущие суммы RA и таким образом получившаяся последовательность RA становится непрерывно монотонной (Рисунок 4.13).
Рисунок 4.12 - Циклические монотонные адреса вызывают столкновение ячеек в RBN. Порты 2 и 6 свободны
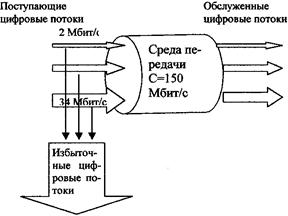
Рисунок 4.13 - Использование дополнительной RAN для накапливания активных ячеек 5 РАСЧЕТ ПРОПУСКНОЙ СПОСОБНОСТИ ЗВЕНА Ш-ЦСИС С ТЕХНОЛОГИЕЙ ATM ПРИ МУЛЬТИСЕРВИСНОМ ОБСЛУЖИВАНИИ 5.1 ПОСТАНОВКА ЗАДАЧИ ПО РАСЧЕТУ ПРОПУСКНОЙ СПОСОБНОСТИ ЗВЕНА Ш- ЦСИС ДЛЯ ПЕРВОГО И ВТОРОГО КЛАССА ПОЛЬЗОВАТЕЛЕЙУточним понятие звена Ш-ЦСИС и определим факторы, влияющие на его пропускную способность. Звено - это участок сети между двумя соседними узлами коммутации. Важнейшим фактором, влияющим на GoS в Ш-ЦСИС, является процедура доступа пользователей в сеть. Эта проблема обусловлена характером трафика. В Ш-ЦСИС пользователь создает информационный поток, битовая скорость которого является случайной величиной. Технология ATM позволяет предоставлять пользователю по требованию переменную ширину полосы битовых скоростей передачи (ШПБСП), а узлы Ш-ЦСИС в режиме коммутации пакетов формируют виртуальный канал с переменной пропускной способностью. В Ш-ЦСИС с ATM различают четыре класса трафика: Класс А - трафик CBR, создаваемый пользователем, передающим информацию с постоянной битовой скоростью; Классы В и С - трафик, создаваемый пользователем, передающим информацию с переменной битовой скоростью (УВК): Класс В - трафик VBR, создаваемый при требовании передачи информации в реальном масштабе времени (real time VBR); Класс С-трафик VBR, не требующий передачи информации в реальном масштабе времени (non-real time VBR); Класс D- разделяется на два подкласса: трафик ABR на доступной битовой скорости и трафик UBR- при неспецифированной битовой скорости Трафик VBR представляет собой наиболее общий тип трафика Ш-ЦСИС. Для определения пропускной способности звена Ш-ЦСИС необходимо оценить влияние фактора трафика VBR. При этом можно воспользоваться понятием эквивалентной ШПБСП. Переход к эквивалентной ШПБСП позволяет свести решение задачи в Ш-ЦСИС к использованию математических моделей. На рисунке 5.1 представлена схема обслуживания заявок и среда передачи, реализующая звено Ш-ЦСИС. Примем что на звене Ш-ЦСИС применен транспортный модуль SDH-STM-1. С учетом структуры модуля диапазон скоростей передачи информации для различных классов пользователей может составлять от 2 до 34 Мбит/с. Если пользователь формирует цифровой поток с плезеохронной скоростью 140 Мбит/с и применяется STM-1, то этот случай является вырожденным. При построении модели звена примем следующие допущения. Каждый
класс пользователей Ki,i=
Рисунок 5.1 Звено моделируется в виде системы массового обслуживания с явными потерями. Если при поступлении вызова ему не может быть представлена требуемая ШПБСП, то вызов считается потерянным. Это соответствует известной модели «потерянные вызовы стираются»- LCC (Lost Call Cleared). Исследования показали, что пропускная способность Ш-ЦСИС зависит от многих факторов, основными из которых являются: o число классов пользователей (источников нагрузки); o величина ПШБСП, необходимая для обслуживания вызовов различных классов пользователей; o характер изменения ШПБСП во времени (источники нагрузки с СВКили VBR); o интенсивности нагрузок, поступающих от пользователей; o принятая процедура управления доступом заявок в сеть. Только учет всей совокупности факторов позволяет оценить вероятностные характеристики GoS, в том числе вероятности потерь вызовов для отдельных классов пользователей, т.е. построить вектор потерь вызовов. Учитывая структурную сложность Ш-ЦСИС, целесообразно сначала рассчитать вероятности потерь на одном звене. Когда решение будет найдено, можно построить вектор потерь, оценив результирующую вероятность потерь между пользователями сети как вероятность потерь "от точки к точке". Если принять, что вероятности потерь вызовов на отдельных звеньях Ш-ЦСИС являются независимыми, то вероятность потерь «от точки к точке»
где Р и Pj -соответственно векторы потерь по вызовам от "точки к точке" и на j-ом звене Ш-ЦСИС на выборочном маршруте; s - число последовательно включенных звеньев. Применим метод резервирования SLM (Sum Limitation Method), основанный на пороговом ограничении доступа для отдельных классов пользователей по критерию суммарного числа используемых ШПБСП. 5.2 МЕТОД РАСЧЕТА ПРОПУСКНОЙ СПОСОБНОСТИ ЗВЕНА Ш-ЦСИС С ATM ТЕХНОЛОГИЕЙМетод включает в себя два этапа. На первом все источники трафика VBR заменяются на источники эквивалентного трафика CBR. Эквивалентность понимается в отношении сохранения значения вероятности потерь пакетов (ATM ячеек) Pcell- Замена источников сводится к пересчету ШПБСП. Эквивалентная ШПБСП для i-го класса пользователей с трафиком VBR при заданной норме на Pcell определиться в виде: K(Pcell)=j(Pcell)m+s2c, (5.2) Где с- скорость передачи на звене; h-максимальное значение ШПБСП i-го класса пользователей для нормализованной битовой интенсивности нагрузки, создаваемой i-м классом пользователей; m и s2 соответственно первый и второй моменты распределения вероятностей ШПБСП во времени; j - коэффициент, зависящий от Pcell Наиболее трудоемкой задачей представляется нахождение значений m и s2 На практике эти величины определяются экспериментально. При этом m вычисляют не непосредственно, а через нормированную максимальную битовую скорость, называемую берстностью. В Ш-ЦСИС скорость передачи информации представляет собой случайный процесс г (t). В силу физических причин всегда существует ограничение максимально допустимой скорости передачи:
Средняя скорость передачи информации за интервал времени Т:
Отношение
Получило название берстности. В Ш-ЦСИС при использовании технологии ATM берстность стала важнейшей характеристикой передаваемой информации. Для различных видов связи и соответственно информации берстность изменяется в широких пределах, на практике В=1...10. Случай В=1 соответствует постоянной скорости передач информации. Второй этап метода включает собственно расчет вероятностных характеристик звена с учетом выполненной на первом этапе эквивалентной замены ШПБСП. В соответствии с постановкой задачи метод используется для двух стратегий управления ресурсом звена - при отсутствии и наличии резервирования ШПБСП. Рассмотрим первый случай, когда доступ пользователей к ресурсу звена не ограничен и Р-ШПБСП нет. Распределение вероятностей числа одновременно занятых ПБСП на звене имеет вид:
Так как в Ш - ЦСИС все пользователи, по условию, имеют равный доступ к ресурсу звена, то имеем полнодоступный пучок и, следовательно,
В этом случае вероятность потерь по вызовам на звене для пользователей класса /:
На основе разработанного метода был построен приведенный ниже алгоритм расчета вероятностных характеристик звена Ш-ЦСИС. 5.3 АЛГОРИТМ РАСЧЕТА ВЕРОЯТНОСТНЫХ ХАРАКТЕРИСТИК ЗВЕНА Ш-ЦСИС 1. Классификация всех пользователей по характеру трафика на CBR- и VBR- пользователей. 2. Выбор значения берстности В для VBR-пользователей. 3. Определение средней скорости передачи, исходя из выбранной берстности и максимальной скорости передачи VBR- пользователя 4. Расчет эквивалентных ШПБСП для всех VBR-пользователей на основе средних и максимальных скоростей VBR- пользователей. 5. Выбор базовой ШПБСП, как наименьшего общего кратного ШПБСП всех CBR- и VBR-пользователей. 6. Определение максимального числа базовых ШПБСП на основе заданной скорости среды передачи. 7. Расчет индивидуальных вероятностей потерь для всех классов пользователей, имеющих доступ к ресурсу звена. 8. Расчет средневзвешенной вероятности потерь. 9. Пересчет фактически поступающих нагрузок пользователей в нормализованные битовые интенсивности поступающей нагрузки звена согласно [5]. 10. Вычисление пропускной способности, выделяемой для каждого класса пользователей, и общей пропускной способности звена. 5.4 РАСЧЕТ ЗВЕНА Ш-ЦСИС С ATM ПРИ МУЛЬТИСЕРВИСНОМ ОБСЛУЖИВАНИИРассмотрим применение предложенного метода на примере расчета звеньев Ш-ЦСИС. Пусть к ресурсу звена имеют доступ два класса пользователей: 1. Стандартные телефонные сообщения, передаваемые по каналам ИКМ— 30/32 и формирующие трафик типа VBR с пиковой скоростью (PCR) 2 Мбит/с, берстностью В=2,5 и допустимой вероятностью потерь ячеек CLR=10-5; 2. Интернет - сообщения, образуемые в ходе просмотра Web-страниц и формирующие трафик типа ABR (доступная битовая скорость) с PCR=2 Мбит/с, берстностью В=10 и CLR=10-8 При проведении расчетов учитывали стандарты ITU-T и предполагали, что звено Ш-ЦСИС использует транспортный модуль STM-1 SDH. Резервирования ресурсов звена нет. Исходные данные для 1-го класса пользователей: Берстность В=2,5 Скорость передачи информации rmax=0.064 Мбит/с Пиковая скорость (PCR) =2 Мбит/с Скорость передачи полезной нагрузки- С=150 Мбит/с Интенсивность поступающей нагрузки - А=80 Эрл Допустимая вероятность потери ячеек CLR=10-5 Исходные данные для 2-го класса пользователей: Берстность В=10 Скорость передачи информации- rmax=0.037 Мбит/с Пиковая скорость (PCR) =2Мбит/с Скорость передачи полезной нагрузки- С=150 Мбит/с Интенсивность поступающей нагрузки – А=8 Эрл Допустимая вероятность потери ячеек CLR=10-8 Решение: Эквивалентная ШПБСП для 1-го класса пользователей с трафиком VBR при заданной норме на Pcell определиться в виде:
Где j(Рcell)=0,273 для Рcell=10-5, Отношение В=rmax/m получило название берстности. Отсюда находим т:
m и s2 соответственно первый и второй моменты распределения вероятностей ШПБСП во времени; К((Рcell)=0,273*0,0256*106+0,0852*150*106=1,091 Мбит/с Таким образом, эквивалентная ШПБСП для 1-го класса пользователей с трафиком VBR равна 1,091 Мбит/с. Суммарное число эквивалентных ШПБСП, требуемых для обслуживания одной заявки 1-го класса пользователей равно 3. Заданный порог резервирования равен единицы, так как резервирования ресурсов звена нет. Эквивалентная ШПБСП для 2-го класса пользователей с трафиком VBR при заданной норме на Рcell определиться в виде:
Где j(Рсе11)=1,581 для Рсе11=10-8, Так как В=rmax/m получило название берстности. Отсюда находим m:
m и s2 соответственно первый и второй моменты распределения вероятностей ШПБСП во времени; K(Pcell)=l,581*0,0037*106+0,0492*150*106=0,366 Мбит/с. Таким образом, эквивалентная ШПБСП для 2-го класса пользователей с трафиком VBR равна 0,366 Мбит/с. Суммарное число эквивалентных ШПБСП, требуемых для обслуживания одной заявки 2-го класса пользователей равно 1. Заданный порог резервирования равен единицы, так как резервирования ресурсов звена нет. Рассмотрим случай, когда доступ пользователей к ресурсу звена не ограничен и резервирования ШПБСП нет. Распределение вероятностей числа одновременно занятых ПБСП на звене имеет вид:
Так как в Ш-ЦСИС все пользователи, по условию, имеют равный доступ к ресурсу звена, то имеем полнодоступный пучок и, следовательно,
В этом случае вероятность потерь по вызовам на звене для пользователей для 1-го и 2-го класса:
Результаты полученные при расчете звена Ш-ЦСИС с ATM при мультисервисном обслуживании для 1-го и 2-го классов пользователей сведены в таблице 1. Таблица 1
6. РАСЧЕТ ЭФФЕКТА СТАТИСТИЧЕСКОГО МУЛЬТИПЛЕКСИРОВАНИЯ В ATM СЕТИ 6.1 МАТЕМАТИЧЕСКАЯ МОДЕЛЬ ТРАФИКА В УЗЛЕ ДОСТУПА И ЦИФРОВОМ ГРУППОВОМ ТРАКТЕ Ш-ЦСИО НА ТЕХНОЛОГИИ ATMТехнология ATM ориентирована на установление соединения. В этом случае можно полагать, что число заявок на предоставление виртуальных соединений, поступающее за существенный временной интервал на i-й абонентский узел или узел доступа, или цифровой групповой тракт (i= 1,2,...,N) от пользователей от k -й службы есть случайный процесс: N где g установление виртуальных соединений от i – го абонента к-ой службы. Имеющийся на сегодняшний день научный, технологический и практический опыт реализации ATM сетей свидетельствует о том, что g N Значение случайного процесса суммирования потока заявок, поступающих на i-ый узел или цифровой групповой тракт от всех к - служб в момент t, составляет [33, 35]: g S i = Суммарное число заявок на предоставление виртуальных соединений от абонентов (источников) всех к - служб i -го узла доступа или цифрового группового тракта в момент t можно пола гать величиной случайной - значением случайного процесса в момент t: |
|

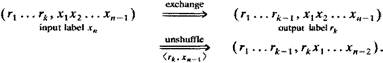
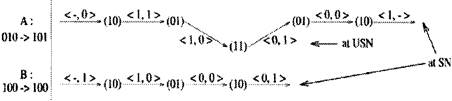
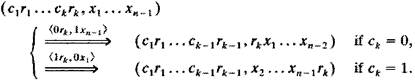
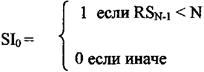

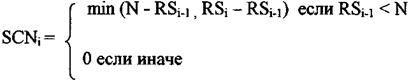
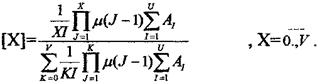 (5.6)
(5.6)