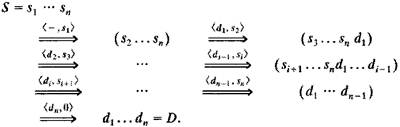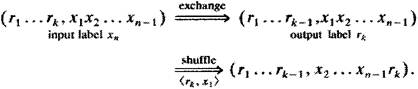|
Рефератырусскому языку полиграфия хозяйство |
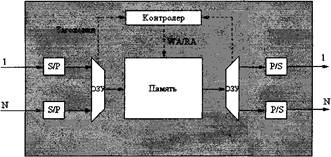
Дипломная работа: Коммутация в сетях с использованием асинхронного метода переноса и доставкиАнализ различных схем маршрутизации и алгоритмов буферизации, применяющихся в ATM-коммутаторах, позволил сформулировать ряд важных принципов их проектирования: обеспечение распределенного управления и высокой степени параллелизма при обработке трафика, реализация функций маршрутизации на аппаратном уровне [10,8,13]. Прежде чем перейти к рассмотрению вариантов организации коммутационного поля, перечислим основные показатели, которыми они характеризуются: - производительность (отношение суммарной скорости выходящего потока к суммарной скорости входящего); - коэффициент использования (отношение средней скорости входящего потока к максимально возможной скорости выходящего); - вероятность потерь ячеек; - задержки передачи ячеек; - длины очередей; - сложность реализации. Ранее методы коммутации подразделяй на пространственные, временные и их комбинации. Предложенная в дальнейшем классификация относит такие методы к одной из следующих категорий: - с разделяемой памятью; - с общей средой; - с полносвязной топологией; - с пространственным разделением (эта категория, в свою очередь, подразделяется на коммутацию, обеспечивающую единственный и множественные пути от входного порта к выходному). Для простоты далее будем рассматривать коммутатор с N входными и N выходными портами и одинаковыми скоростями портов, равными К ячеек/с. 2.15 МЕТОД РАЗДЕЛЯЕМОЙ ПАМЯТИБазовая структура коммутатора с разделяемой памятью приведена на рисунке 2 [8,9]. Входящие ячейки преобразуются из последовательного формата в параллельный и записываются в порт ОЗУ. Используя заголовки ячеек с тэгами маршрутизации, контроллер памяти решает, в каком порядке ячейки будут считываться из нее. Выходящие ячейки демультиплексируются при передаче на выходные порты и преобразуются из параллельного формата в последовательный.
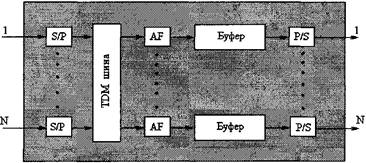
Рисунок 2.2 - Структура коммутатора с разделенной памятью: RA - чтение адреса; WA- запись адреса; S/P – последовательно параллельное преобразование; P/S - параллельно-последовательное преобразование Данный метод подразумевает организацию очередей на выходных портах, где все буферы формируют единое пространство памяти. Он привлекателен тем, что дает возможность вплотную приблизиться к теоретическому пределу производительности. Совместный доступ к буферной памяти минимизирует ее емкость, удерживая долю потерянных ячеек в заданных границах: при резком росте интенсивности трафика в направлении какого-либо выходного порта разделение памяти позволяет максимально сгладить пик нагрузки за счет использования свободной части буфера. Коммутатор Prelude, разработанный фирмой СМЕТ, был одним из первых устройств, применяющих тактированную обработку с групповой буферизацией. Другие широко известные примеры — коммутатор с разделяемой буферной памятью компании Hitachi и устройство GCNS-2000 корпорации AT&T. Правда, этот метод не свободен от недостатков. Разделяемая память должна работать по крайней мере в N раз быстрее одиночного порта, поскольку ячейки считываются и записываются в память последовательно. Время доступа к памяти — конечная величина, как и произведение числа портов на скорость обмена через порт (NV). Кроме того, необходимо, чтобы централизованный контроллер памяти успевал обрабатывать заголовки ячеек и тэги маршрутизации с той же скоростью, что и память. Чтобы преодолеть серьезные технические трудности, возникающие при использовании множественных классов приоритета трафика, при сложном распределении ячеек, многоадресной и широковещательной передаче, требуется высокое быстродействие памяти и контроллера [1,16]. 2.16 МЕТОД ОБЩЕЙ СРЕДЫЯчейки могут передаваться через общую среду — кольцо, шину или двойную шину. Примером данного метода является шина с временным разделением (ТОМ), представленная на рисунке 3. Входящие ячейки передаются на шину циклически. На каждом выходе адресные фильтры (Address Filter, AF) в соответствии с тэгами маршрутизации считывают и пересылают свои ячейки в выходные буферные устройства. Дабы не допустить переполнения входной очереди, скорость шины должна быть равной по крайней мере NV ячейкам/с [8,9].
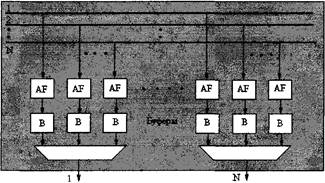
Рисунок 2.3 - Коммутатор с общей средой на базе шины с временным разделением: AF- адресный фильтр; S/P – последовательно-параллельное преобразование; P/S – параллельно-последовательное преобразование Модуляция выходных каналов упрощает работу адресных фильтров, а широковещательная передача с селекцией — функционирование всей системы. На методе общей среды основана работа нескольких коммутаторов, включая Paris и plaNet компании IBM, Atom корпорации NEC, Fore-Rurmer ASX-100 производства Fore Systems, Синхронная коммутация составных пакетов (Synchronous Composite Packet Switching, SCPS), использующая множественные кольца, — еще один вариант коммутации с обшей средой. Следует отметить, что возможности масштабирования коммутаторов данного типа оказываются ограниченными, поскольку адресные фильтры и выходные буферы должны действовать со скоростью, в N раз превосходящей скорость передачи портов. Кроме того, выходные буферы здесь не являются общими для N портов, а значит, для сохранения прежней вероятности потерь ячеек требуется, большая суммарная емкость буферов, чем в случае применения метода с разделяемой памятью [16]. 2.17 МЕТОД ПОЛНОСВЯЗНОЙ ТОПОЛОГИИОтличительная особенность данного метода — существование независимого пути для каждой из N2 возможных пар входов и выходов (рисунок 2.4). Таким образом, входящие ячейки транслируются на раздельные шины выходных каналов, а адресные фильтры пропускают эти ячейки в выходные очереди [14].
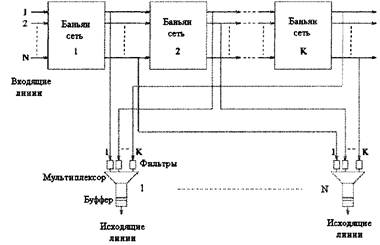
Рисунок 2.4 – Коммутатор с полносвязанной топологией: AF- адресный фильтр; В – буферы Преимущества рассматриваемого типа коммутации заключаются в том, что буферизация ячеек происходит на выходных портах и (как в методе с общей средой) отсутствуют ограничения на групповую и широковещательную передачу. Реализация адресных фильтров и выходных буферов достаточно проста: нужно лишь обеспечить требуемую скорость обмена через порт. Метод полносвязной топологии допускает простое масштабирование в широких пределах и позволяет достичь высокой скорости функционирования коммутатора, поскольку все его аппаратные модули работают с одной и той же скоростью. Примерами использования описанного подхода являются устройства с матричной шиной фирмы Fujitsu и система SPANet компании GTE. К сожалению, квадратичный рост числа буферов ограничивает количество выходных портов, хотя скорость обмена через порт лимитируется только физическим быстродействием адресных фильтров и выходных буферов. Устройство The Knockout, разработанное AT&T, было первым прототипом коммутаторов, в которых число буферов уменьшалось ценой небольшого увеличения потерь ячеек. Вместо N буферов на каждом выходе использовалось меньшее фиксированное число буферов L, а общее число буферов составляло NL. Этот подход базируется на предположении, что вероятность одновременного поступления на выходной порт более L ячеек мала. Оказывается, при больших N произвольных (но однородных) параметрах трафика восьми буферов на порт достаточно для удержания доли потерь в пределах одной ячейки из миллиона [14,8]. 2.18 МЕТОД ПРОСТРАНСТВЕННОГО РАЗДЕЛЕНИЯПростейшим примером системы с пространственным разделением является коммутатор матричного типа, обеспечивающий физическую взаимосвязь с любым из N входных и N выходных портов. Хорошо известны коммутаторы матричного типа с производительностью в сотни гигабит в секунду, в которых применяются входная и/или выходная буферизация и двунаправленный алгоритм разделения памяти. В целях сокращения числа коммутационных элементов (кроссов), которые необходимы для внутренней коммутации каналов, организации взаимосвязей между вычислительными узлами в многопроцессорных системах и, позднее, коммутации пакетов и ячеек ATM, были разработаны многокаскадные сети (Multistage Interconnection Network, MIN), представляющие собой древовидные структуры [6,12]. Баньяновидные сети (свое название они получили потому, что схожи по форме с одноименным тропическим деревом), один из наиболее широко представленных типов сетей MIN, строятся путем формирования каскадов коммутационных элементов [5,6,12]. Основной коммутационный элемент 2x2 обрабатывает входящую ячейку в соответствии с управляющим битом выходного адреса. Если этот бит равен нулю, то ячейка направляется на верхний выходной порт кросса, в противном случае — на нижний.
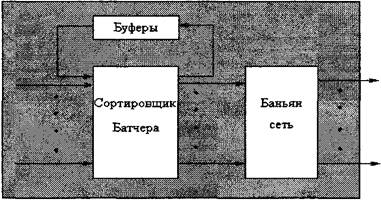
Рисунок 2.5 - Баньяновидная сеть 8x8 На рисунке 2.5 показано последовательное соединение коммутационных элементов, формирующих Баньяновидную сеть 8x8. Сеть 8x8 формируется рекурсивно, при этом первый бит применяется для транспортировки ячейки через первый каскад, а последние два бита — для маршрутизации ячейки через сеть 4x4 на соответствующий выходной порт. Итак, в Баньяновидной сети N´N n-й каскад выбирает направление передачи ячейки по n-му биту выходного адреса. При N=2n такая сеть состоит из (N/2)\log N элементарных двоичных кроссов. Сети MIN способны автоматически обновлять таблицы маршрутизации (т.е. имеют свойство самомаршрутизации), в случае если выходной адрес полностью определяет маршрут следования ячейки через сеть. Популярность Баньяновидных сетей объясняется использованием простых коммутационных элементов для обеспечения процесса коммутации; при этом ячейки передаются параллельно и все элементы действуют с одной и той же скоростью (так как нет дополнительных ограничений на размер N или скорость V). При создании больших коммутаторов указанные свойства позволяют легко реализовать модульный рекурсивный подход на уровне аппаратных средств. Коммутаторы Sunshine компании Bell-core и 1100 подразделения Alcatel Data Networks — типичные примеры устройств, в которых применяется данный подход. Отрицательным свойством Баньяновидных сетей является их принадлежность к блокирующим схемам, причем вероятность блокировки ячейки при ее маршрутизации быстро возрастает с ростом сети [8]. Очевидно, что в таких сетях существует единственный путь с любого входного порта на любой выходной. Регулярные Баньяновидные сети используют только один тип коммутационных элементов. В их разновидности (так называемых SW-Баньяновидных сетях) вероятность блокировки ячеек удается уменьшить, применяя кроссы больших размеров, они строятся рекурсивно из коммутационных элементов размером L´М, где L>2 и М>2. Дельта-сети представляют собой подкласс SW - Баньяновидных сетей и обладают свойством самомаршрутизации. Существует несколько типов дельта-сетей: прямоугольная (кроссы имеют одинаковое число входов и выходов), базовая (baseline), омега, флип, куб, обратный куб и др. Сеть дельта-b размером N´N содержит logbN каскадов, причем каждый каскад состоит из N/b коммутационных элементов b´Ь. Как уже говорилось, число точек коммутации в Баньяновидных сетях меньше N2, что может приводить к конфликту маршрутов двух ячеек, адресованных на разные выходные порты. При возникновении подобной ситуации, именуемой внутренней блокировкой, лишь одна из двух ячеек способна достичь следующего каскада, а в результате общая производительность снижается. Одно из решений проблемы состоит в добавлении специальной сети предварительной сортировки (например, так называемого сортировщика Батчера), которая направляет ячейки в Баньяновидную сеть. Сортировщик позволяет избежать блокировок при адресации ячеек на различные выходные порты, но если они одновременно адресуются на один и тот же выход, единственным решением становится буферизация [8,1,14]. 2.19 РАЗДЕЛЕНИЕ БУФЕРОВЧисло и размер буферов имеют важное значение при разработке коммутатора. В устройствах с общей памятью централизованный буфер зачастую имеет преимущество перед средствами статистического разделения. Принимая интенсивный поток ячеек на некоторый выходной порт, коммутатор выделяет для них максимально возможную часть буферного пространства, что приводит к экономии последнего, поскольку ячейки поступают на различные порты случайным образом [1,12]. Для коммутационного поля с TDM-шиной и N выходными буферами большая группа ячеек, одновременно поступивших на какой-либо выход, естественно, не может быть принята другим выходным буфером. Тем не менее каждый выходной буфер способен статистически мультиплексировать трафике N входов. В структурах с N2 выходными буферами, имеющих полносвязную топологию, статистическое мультиплексирование между выходными портами или на любом выходном порте невозможно. В этом случае размер буферного пространства растет экспоненциально. Буферы могут быть установлены на входе сети Батчера (рисунок 2.6).
Рисунок 2.6 - Входная буферизация Однако в этом случае возможна блокировка очереди ячейкой, находящейся в ее начале направляемой на занятый выходной порт, даже если выходные порты ячеек, расположенных позади данной, свободны [1,3,5]. В такой ситуации способна выручить дисциплина «пришедший первым обслуживается в случайном порядке» (First In Random Out, FIRO), но, к сожалению, она не имеет простой реализации. Другой способ избежать конфликтов маршрутов — установить буфер непосредственно внутри коммутационных элементов Баньяновидной сети. Если две ячейки одновременно направляются в один и тот же выходной канал, одна из них буферизуется внутри коммутационного элемента. Внутренняя буферизация используется и механизмом управления с помощью обратной блокировки (backpressure): очереди в одном каскаде сети задерживают ячейки предыдущего каскада сигналом обратной связи. Влияние процедуры обратной блокировки может достигнуть первого каскада и привести к созданию очередей на входах. Следует отметить, что внутренняя буферизация способна вызвать блокировку ячейки в начале очереди на каждом коммутационном элементе и, следовательно, не позволяет достичь максимальной производительности. Еще один вариант — использование рециркуляционного буфера, внешнего к коммутационному полю (рисунок 2.7).
Рисунок 2.7 - Рециркуляционные буферы Этот подход применяется в широкополосных цифровых коммутаторах Sunshine фирмы Bellcore и Starlite компании AT&T. В данном случае конфликты на выходе обнаруживаются после прохождения сортировщика Батчера, затем сеть выбирает ячейку для дальнейшей передачи, а оставшиеся ячейки через рециркуляционный буфер возвращаются на входные порты сети Батчера. К сожалению, данный метод требует сложного приоритетного управления для сохранения исходной последовательности передаваемых ячеек и применения сети Батчера большего размера для размещения рециркулированных ячеек. Помимо рассмотренных выше видов Баньяновидных сетей существует немало типов сетей.M1N с множественными путями между входными и выходными портами. Классическими примерами являются неблокирующие сети Бэнеша и Клоза, сети со свойством самомаршрутизации и распределением нагрузки, снижающими потребность во внутренней буферизации, групповые Баньяновидные коммутационные структуры (например, тандем Баньянов). Для формирования таких сетей возможно параллельное использование нескольких Баньяновидных соединительных сетей [8,9]. Сети MIN с множественными путями обеспечивают более однородное распределение трафика, необходимое для минимизации внутренних блокировок и повышения отказоустойчивости [14]. Тем не менее если ячейки направляются по независимым путям с переменными задержками, необходимо предусмотреть сохранение исходной последовательности ячеек в виртуальном соединении на выходном порте. Поскольку данный процесс может потребовать значительных затрат вычислительных ресурсов процессора, предпочтительнее выбирать путь передачи ячеек на стадии установления и использовать его в течение всего времени существования соединения. Особое внимание должно уделяться предотвращению блокировки последовательных вызовов. 2.20 ОТКАЗОУСТОЙЧИВОСТЬПоскольку надежность является существенным аспектом функционирования коммутационных систем, необходимо обеспечить избыточность их критически важных компонентов. Поле маршрутизации и структура буферов, являющиеся важнейшими элементами коммутационной системы, могут быть продублированными или избыточными, что влияет на организацию механизмов обнаружения отказов и восстановления работоспособности [15]. Простейший способ повышения надежности сводится к разбиению всей совокупности коммутируемых ячеек на непересекающиеся подмножества, распределяемые между параллельными плоскостями поля маршрутизации. Этот метод весьма эффективен, так как он обеспечивает наименьшую избыточность, а каждая плоскость несет лишь малую долю общего трафика. Другой вариант — тождественное дублирование всего множества ячеек — обеспечивает большую отказоустойчивость при меньшей производительности. Компромиссным решением может быть использование частично перекрывающихся подмножеств. Распараллеливание плоскостей поля маршрутизации и структуры буферов поднимает степень отказоустойчивости, однако гораздо важнее повысить избыточность в пределах отдельных плоскостей. Баньяновидные сети склонны к отказам, поскольку содержат единственный путь в каждой паре «вход—выход»; сети с множественными путями отличаются большей отказоустойчивостью. Для повышения избыточности следует включать в состав Баньяновидных сетей дополнительные коммутационные элементы и каскады, избыточные и альтернативные соединения либо увеличивать число входных и выходных портов. Платой за это становится усложнение как схем буферизации и маршрутизации, так и средств управления [8]. Для организации эффективного контроля за отказоустойчивостью коммутационной системы применяются разнообразные тестирующие механизмы. Маршрутизация специальных ячеек через тестовые элементы и отслеживание их появления на выходах, а также добавление служебной информации в заголовок ячейки позволяют обнаружить потери ячеек, ошибочные пути или неоправданные задержки. При выявлении отказа трафик перераспределяется до устранения причины сбоя, причем функция перераспределения может выполняться как концентраторами, так и самим коммутационным полем. 3 ОСНОВЫ БАНЬЯН-КОММУТАЦИИ 3.1 БАНЬЯН СЕТИОтличительное свойство Баньян сети - это существование перехода от любого входа к любому выходу [8],
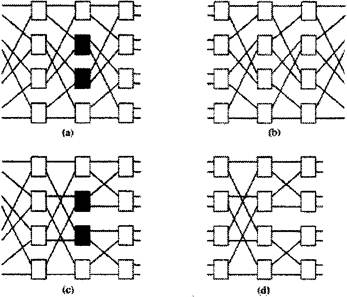
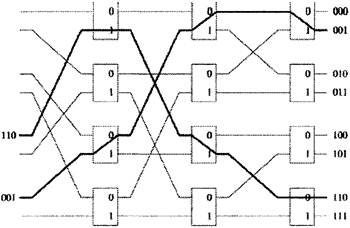
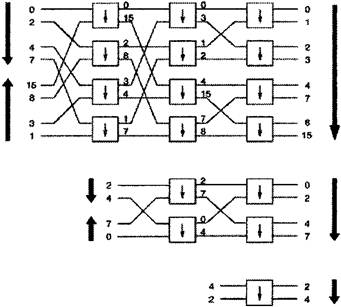
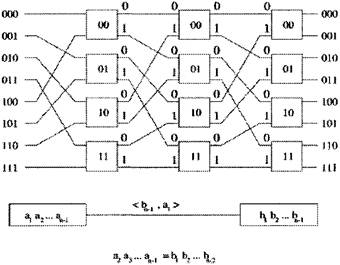
Рисунок 3.1- показывает четыре вида сетей, принадлежащих к этому классу: а) смешанные (Омега) сеть; b) реверсная смешанная сеть; c) особо чувствительная Баньян сеть; d) обыкновенная сеть; Основное свойство этих сетей: 1. Они состоят из n=log2N и N/2 узлов на уровень. 2. Они имеют самонастраивающееся свойство - уникальный n-битный адрес назначения может использоваться для передачи ячейки от любого входа к любому выходу, по одному биту на каждый уровень. 3. Их регулярность и взаимосвязная схема очень привлекательна для применения в VLSI (VLSI - сверх большая степень интеграции). Рисунок 3.2 показывает пример соединения в Баньян сети 8´8, где темные линии отражают передающие пути. С правой стороны адрес каждого выходного сигнала обозначен как ряд n-битов, b1...bn. Адрес ячейки сигнала закодирован в заголовке ячейки. На первом уровне проверяется бит b1, если это 0, ячейка будет выдвинута на высший, исходящий уровень; если это 1,то ячейка отправляется на низший уровень. На следующем уровне проверяется бит b1, передача сигнала происходит аналогично.
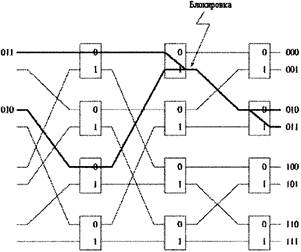
Рисунок 3.2 - Баньян сеть 8´8 Внутренняя блокировка происходит в случае когда ячейка потеряна из-за конфликтных ситуаций на уровне сети. Рисунок 3.3 приводит пример внутренней блокировки внутри Баньян сети 8x8. Тем не менее, Баньян сеть не будет иметь внутренних блокировок, если будут соблюдены следующие условия [12]: · Нет свободного входного сигнала между любыми двумя активными входами. · Выходные адреса ячеек находятся либо в прямом, либо в обратном порядке.
Рисунок 3.3 - Блокировка в Баньян сети 8´8
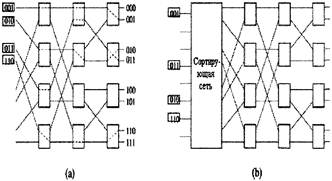
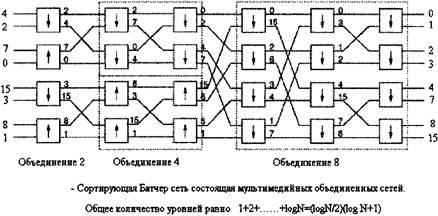
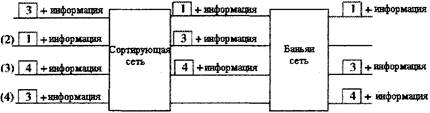
Рисунок 3.4 (a) - Не блокируемая Баньян сеть для входных сигналов (b) - Сортирующая Баньян сеть Рассмотрим рисунок 3.4. Предположим, что Баньян сети предшествует сети которая накапливает ячейки и сортирует их, учитывая их выходные значения. Получившаяся в результате структура является деблокирующей сортирующей Баньян сетью. 3.2 СОРТИРУЮЩАЯ БАТЧЕР СЕТЬЭта сеть формируется серией объединенных сетей различных размеров [12,14]. Рисунок 3.5 демонстрирует сортирующую Батчер сеть 8x8, состоящую из объединенных сетей трех различных размеров. Объединенная сеть на рис.3.6 состоит из 2´2 сортирующих элементов в каскадах, и схема соединения между каждой парой смежных каскадов аналогична схеме Баньян сети. Можно заметить, что если адреса первой половины входящих ячеек расположены в возрастающем порядке, а адреса второй половины - в убывающем, то объединенная сеть будет сортировать ячейки на выходе в прямом порядке. Сортирующая сеть 8´8 будет сформирована, если 8´8 объединенной сети предшествуют две объединенных сети 4´4 и четыре объединенных (сортирующих) элемента 2´2. Произвольный список из восьми входных ячеек будет распределен сначала на четыре списка по две ячейки, а затем - в два списка по четыре ячейки и наконец - в список из восьми ячеек. Объединенная сеть N´N состоит из log2N уровней и (N log2N)/2 уровней. Сортирующая сеть имеет 1+2+......+ log2N=(log2N)(log2N+l)/2 уровней и (N log2N)(log2N+l)/2 элементов [14].
Рисунок 3.5 - Сортирующая Батчер сеть 8´8
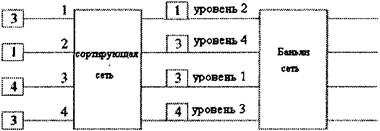
Рисунок 3.6 - Структура передающей сети 3.3 АЛГОРИТМЫ РАЗРЕШЕНИЯ КОНФЛИКТОВ НА ВЫХОДЕ3.3.1 ТРЕХФАЗОВАЯ РЕАЛИЗАЦИИСледующий 3-х эталонный алгоритм является решением для выходного спорного сигнала в Батчер-Баньян коммутаторе.(рис 3.7(а)).
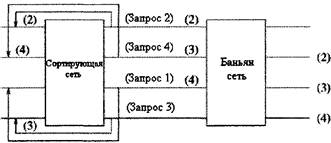
Рисунок 3.7 - 1 этап: отправка запроса В первую фазу алгоритма (фазу арбитража) каждый вводной порт I посылает в сортирующую сеть краткий запрос, содерж6щий только информацию об источнике и назначении (ячейки). В сортирующей сети ячейки рассматриваются в порядке возрастания, по адресам их назначения. Запросы сортируются все вместе и выбирается тот, чей адрес назначения отличен от предыдущего в сортировочном списке [14,17]. Поскольку результаты арбитража не известны входным портам, выбранные запросы посылают уведомление своим вводным портам через взаимосвязанную сеть во вторую фазу (фазу уведомления). Сеть с обратной связью представлена на рисунке 3.7(в), состоит из N фиксированных соединений, каждый выход сети Батчера соединен с входом сети Батчера.
Рисунок 3.8 - 2 этап: уведомление решающих портов Каждое подтверждение несет источник, который получил разрешение на вход Батчер сети. Эти источники проходят через всю Батчер-Баньян сеть на различные выхода, учитывая адрес источника. Когда трассировка уведомлений обратно через идентичную специализированную сеть ко вводам закончена, выводы узнают свои результаты арбитража. Вводам, получившим уведомление, обеспечивается бесконфликтный вывод ячеек.
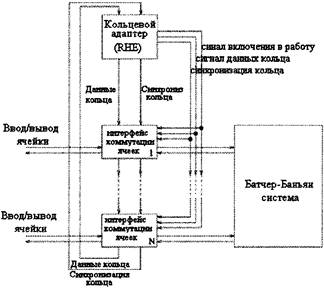
Рисунок 3.9 - 3 этап: отправка ячеек с информацией Эти входные порты перемещают полную ячейку на третьем последнем этапе, через такую же Батчер-Баньян сеть (рисунок 3.7(с)). Вводы, не получившие уведомления, сохраняют свои ячейки в буфере следующего трехфазового цикла. 3.3.2 КОЛЬЦЕВОЕ РЕЗЕРВИРОВАНИЕВ Баньян коммутаторе с накопителем предусмотрено кольцевое резервирование (рисунок 3.10). Этот коммутатор состоит из Баньян коммутационной системы с накопителем, нескольких коммутационных интерфейсов, кольцевой адаптер (RHE) и синхронизатора [17,19].
Рисунок 3.10 - Батчер - Баньян коммутатор с кольцевым резервирование Интерфейс коммутатора осуществляет кольцевое резервирование, буферизацию входящих ячеек, синхронизацию ячеек, отправленных в коммутационную систему и буферизацию ячеек на выходе. Входящие в коммутатор ячейки буферизуются в FIFO, до резервирования. Когда резервирование на выводе успешно завершено, ячейка доставляется в коммутационную систему в начале следующего цикла. После этого следующая ячейка из очереди может проходить резервирование. При выходе из коммутационной системы, ячейка буферизуется в интерфейс, чтобы затем быть переданной по назначению RHE дает два сигнала синхронизации в коммутаторе: (синхронизации битов и начала цикла), три сигнала кольцевого резервирования (сигнал включения в работу кольца, сигнал данных кольца и синхронизации кольца). Сигнал данных кольца - это серия битов выходного резервирования, а сигнал синхронизации кольца указывает местоположение первого выходного порта в серии кольцевых данных. Эти два сигнала циркулируют через RHE и интерфейсы коммутатора по одному биту каждый раз, в течение всего процесса резервирования. Кольцевое резервирование происходит в начале каждого цикла, после того, как каждый кольцевой интерфейс получает заголовки копий самых старших ячеек. С началом каждого цикла данные кольца в RHE и каждый кольцевой интерфейс устанавливаются в исходное состояние («свободно»). Серии кольцевых данных начинают затем циркулировать через интерфейс бит за битом. Каждый интерфейс имеет портовой счетчик, который увеличивается (дает приращение) при каждом прохождении бита кольцевых данных. Каждый временной интервал портовой счетчик сравнивается с адресом назначения самой старшей ячейки для того, чтобы определить, должна ли ячейка быть отправлена на выход в следующий промежуток. При прохождении бита данных кольца, все интерфейсы коммутатора рассматривают кольцевую синхронизацию и кольцевые данные бита. Если сигнал кольцевой синхронизации верен, (это значит, что следующий бит кольцевых данных соответствует первому выводу), тогда портовой счетчик устанавливается в исходное состояние при прохождении следующего бита. Если назначение ячейки согласовано с портовым счетчиком и бит данных кольца свободен, интерфейс коммутатора делает на кольце запись «занято», означающую, что в следующий коммутационный цикл вывод будет занят. Если бит данных кольца уже занят, или если портовой счетчик не согласован с назначением старшей ячейки, бит данных кольца не изменяется. Т.к. каждый коммутационный цикл интерфейса делает не более одного резервирования, конфликтные ситуации в коммутационной системе исключены. Во время кольцевого резервирования, ячейки, зарезервированные в предыдущий коммутационный цикл, отправляются в коммутационную систему. На рисунке 3.11 показано, что в первый промежуток времени согласуются адреса выходных портов ячеек из вводов 1 и 5, и используются пункты, обозначающие, что ячейки могут пройти в эти порты. Ячейкам которые отмечены битами X1 и Х5 присваивается одно значение, указывающее на то, что выходные порты 1 и 5 уже заняты. Все отмеченные биты сдвигаются в сторону одного, и значения счетчиков так же увеличиваются на один по модулю во второй временной интервал. Во второй и третий промежутки времени согласования не происходит. В четвертый согласовываются адреса выходных портов ячеек из 0 и 2 вводов. Т.к. выходной порт 5 уже был зарезервирован для ячейки (на которой указано значение отмеченного бита X5)
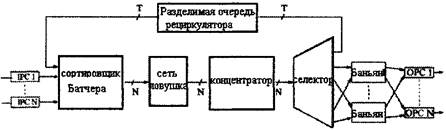
Рисунок 3.11 - Схема реализации кольцевого резервирования в предыдущий временной интервал, то ячейка у входа 2 не может быть отправлена. В пятый и шестой промежутки времени ячейки у вводов 3 и 4 так же не могут быть отправлены к выводам 1 и 3 соответственно, т.к. уже были зарезервированы в предыдущий временной интервал. В итоге ячейки у входных проверенных портов оказываются в конфликтной ситуации. В данном примере арбитражный цикл может быть завершен за шесть временных интервалов, поскольку имеется шесть входных портов. В этой схеме используется серийный механизм, и в целом арбитражный цикл может состоять из N бит временных интервалов, где N обозначает число портов ввода и вывода коммутатора, что может стать критическим параметром при большом количестве портов. Однако, эта схема обеспечивает равноправие портов, произвольно устанавливая нужные значения счетчиков перед арбитражем. Эта схема может быть использована на вводах любой коммутационной системы. 3.4 СОЛНЕЧНЫЙ КОММУТАТОРВ этом коммутаторе сочетается сортирующая Батчер сеть и параллельно-направляющая Баньян сеть. Таким образом, к каждому выводу подходит более одного канала. На рис. 3.12 дана блок-схема строения этого коммутатора [17,18,19]. Параллельная сеть маршрутизации с автоблокировкой k обеспечивает k отдельных трактов каждому выводу. Если более, чем k ячеек делают запрос на определенный вывод за один временной интервал, тогда часть ячеек отправляется в очередь общей рециркуляции и затем снова передаются в коммутационную систему к назначенным вводам. Очередь рециркуляции состоит из Т параллельных цепей и Т назначенных вводов в сортирующую сеть с накопителем. Каждая цепь рециркуляции может сохранять одну ячейку. В каждой цепи имеется блок задержки для выстраивания рециркулирующих ячеек с ячейками, прибывшими из контролирующих устройств вводных
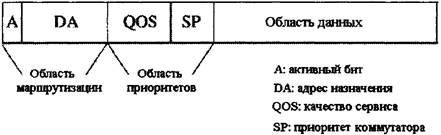
Рисунок 3.12 - Блок-схема солнечного коммутатора каналов (IPC) в следующий временной интервал. В течение каждого интервала сеть с накопителем сортирует новоприбывшие и рециркулирующие ячейки в порядке приоритета и адресов назначения. Это позволяет заграждающей сети, выбирая k ячейки высшего приоритета для каждого вывода, разрешать конфликты у выходных портов. Поскольку в устройстве существует k параллельных сетей с автоблокировкой, каждый вывод может принимать k ячеек каждый временной интервал. Если для одного вывода назначено больше, чем k ячеек, их излишек будет отправляться в очередь рециркуляции. Концентратор и селектор направляют лишние ячейки в цепи рециркуляции, а выбранные ячейки будут направлены в сети с автоблокировкой. Каждая ячейка проходит в контролер входного порта со служебным заголовком. В него входят два контрольных поля: поле трассировки и приоритетное поле (рисунок 3.13).
Рисунок 3.13- Формат заголовка Оба упорядочиваются, начиная с наиболее значительного бита. В поле трассировки первый бит -бит активности ячейки, указывающий, содержит ли ячейка значимую информацию (А=1) или она пуста (А=0). Затем следует поле адресов назначения (DA), определяющее нужный выходной порт. Приоритетное поле состоит из индикатора качества и класса услуг передачи (QoS) и внутреннего приоритета коммутатора (SP). QoS поле различает ячейки услуг высшего приоритета и услуг низшего приоритета. К первым относится схемная эмуляция, а ко вторым услуги без установления связи. QoS поле следит за тем, чтобы в случае конфликта, ячейки высшего приоритета трассировались первыми. SP поле используется коммутатором для указания числа временных интервалов, в течение которых задерживалась ячейка. Оно также дает высший приоритет рециркулирующим ячейкам. Поэтому ячейки из данного источника трассируются последовательно. При сортировке ячейки распределяются в возрастающем порядке их адресов назначения. Приоритетное поле, в котором высшее численное значение соответствует высшему уровню приоритета, является продолжением поля трассировки. Это является причиной того, что ячейки, назначенные в один порт выхода, располагаются в убывающем порядке приоритета. В сети заграждения адреса ячеек сравниваются с адресом ячейки, находящейся на k позиций выше. Если они совпадают с адресом ячейки, стоящей на k позиций выше (а это значит, что имеется, по крайней мере, k ячеек высшего приоритета), они отмечаются и отправляются на рециркуляцию. Их поля трассировки заменяются приоритетными полями, т.к. последние важнее для последующей работы сортирующей системы и предотвращения потерь ячеек при рециркуляции. Если их адреса не совпадают, значит ячейка является одной из k ячеек высшего приоритета и может трассироваться. В концентрационных сетях с накопителем существует две группы ячеек: одна для трассировки, другая для рециркуляции. Обе группы сортируются в непрерывные списки. Чтобы предотвратить блокирование в сети с автоблокировкой, группа ячеек трассируется из списка в восходящем порядке адресов. Группы ячеек для циркуляции сортируются в отдельный список в порядке приоритета и адресов назначения. Если очередь рециркуляции переполняется, для ячеек, направленных в выводы с высокими номерами, больше вероятности быть удаленными, чем для ячеек, направленных в выводы с низкими номерами. Затем, ячейки направляются в селектор, который разделяет их на две группы и направляет их либо в k сеть с автоблокировкой, либо в Т рециркуляторы. Ячейки, попадающие в рециркулятор, изменяют поля приоритета и трассировки в первоначальный формат. После рециркуляции их приоритет (SP) повышается [14]. Выводы селекторов распределены между k сетями с автоблокировкой, путем соединения k выводов с соответствующей сетью с автоблокировкой. Поэтому, если две ячейки назначены в один вывод, они будут направляться в разные сети с автоблокировкой. В каждой сети с автоблокировкой ячейки формируют непрерывные списки, направленные в определенные выводы, что обеспечивает деблокирование в сети с автоблокировкой. Каждая ячейка достигает нужного вывода в сети с автоблокировкой, и затем все соответствующие выводы группируются и образуют очередь в контролере выходного порта (ОРС). 3.5 МАРШРУТИЗАЦИЯ С ОТКЛОНЕНИЕМ3.5.1 ТАНДЕМНЫЙ (СПАРЕННЫЙ) БАНЬЯН КОММУТАТОРНа рисунке 3.14 изображена тандемная коммутационная Баньян сеть (TBSF) [17].
Рисунок 3.12 - Тандемная коммутационная Баньян сеть Данная сеть состоит из множества Баньян сетей. При конфликте ячеек в каком-либо узле системы, одна из них будет отклоняться в неверный вывод узла и придет по неверному адресу назначения в Баньян сети. Затем отклонившаяся ячейка передается в следующую Баньян сеть. Этот процесс повторяется до тех пор, пока ячейка не достигнет нужного вывода, или же пока она не выйдет в неверный вывод последней Баньян сети и, таким образом будет считаться потерянной. Каждый вывод Баньян сети соединен с соответствующим выходным буфером. Каждая отклонившаяся ячейка отмечается, чтобы ее можно было отличить от ячейки, идущей верно и не изменит ее маршрута в последующих каскадах сети. На выводах каждой Баньян сети, все ячейки, достигшие своего пункта назначения, извлекаются из коммутационной системы и буферизуются. Таким образом, нагрузка в последовательно соединенных Баньн сетях, а также вероятность конфликтов уменьшается. При достаточно большом числе таких последовательно соединенных сетей, можно уменьшить коэффициент потерь до желаемого. Численные результаты показывают, что каждая, добавленная к этой последовательности Баньян сеть, уменьшает вероятность потерь на один порядок величины. TBSF работает следующим образом. К каждой входящей в коммутационную систему ячейке прилагается коммутационный заголовок, содержащий 4 следующих поля: 1. Бит активности а: указывающий, содержит ли область ячейку (я=1) или она пуста(я=0). 2. Бит конфликтов с: указывающий, отклонялась ячейка в предыдущих каскадах данной сети (с=1) или нет (с=0). 3. Приоритетно поле Р: оно является факультативным и используется при наличии в коммутаторе большого числа приоритетов. 4. Адресное поле D: содержащее адреса назначений d1, d2,...dn n=(log2N). Состояние коммутационного элемента в каскаде s сети с автоблокировкой первоначально определяется тремя битами в заголовке двух вводимых ячеек, а именно а, с, ds. При большом количестве приоритетов используется так же поле Р. В следующем алгоритме биты, обозначенные 1 и 2, соответствуют двум вводным ячейкам. 1. Если а1=a2=0, ничего не предпринимайте. 2. Если а1=1, a a2=0, установите коммутатор в соответствии с ds1 3. Если а1=0, а2=1, установите коммутатор в соответствии с ds2 4. а1=а2=1, тогда а) если c1=c2=1, ничего не предпринимайте б) если c1=0, а c2=1, установите коммутатор в соответствии с ds1 c) если c1=1, а c2=0, установите коммутатор в соответствии с ds2 d) если c1=c2= 0, тогда: I. если P1>P2, то установите коммутатор в соответствии с ds1 II. если P1<Р2, то установите коммутатор в соответствии с ds2 III.если Р1=Р2, то установите коммутатор в соответствии с ds1 или ds2. Чтобы уменьшить число буферизуемых на каждом каскаде битов при выполнении этого алгоритма и сократить задержку, адрес бита помещается в исходное положение адресного поля. Для этого нужно циклически сдвигать адресное поле на один бит в каждом каскаде. Таким образом, можно сократить задержку до времени, соответствующего прохождению 3-х бит, в каждом каскаде, без учета поддержки множественного приоритета и сохранять ее постоянной.С конфликтным битом легко отличить ячейки, отклонившиеся от маршрута и ячейки с верным маршрутом на выходе каждой сети с автоблокировкой: если с=0, значит ячейка трассировалась верно, а если с=1, значит эта ячейка отклонилась. Ячейка с c=0 буферизуется и не принимается следующей сетью с автоблокировкой. Ее бит активности становится равным 0. Ячейка с с=1 не буферизуется на выходе, но принимается следующей сетью с автоблокировкой, и ее конфликтный бит становится = 0 для дальнейшей маршрутизации. Все ячейки, поступающие в тандемный Баньян коммутатор за один временной интервал, синхронизируются по тактам через всю коммутационную систему. Если не учитывать задержки на распространение сигнала, то задержка каждой ячейки в сети постоянна и равна п задержкам на обработку в коммутационном элементе, что составляет временную разницу прибытия двух ячеек из соседних Баньян сетей. Для того, чтобы ячейки из разных сетей поступили в выходной буфер одновременно, между каждым выводом и Баньян сетью можно поместить соответствующий элемент задержки. Кроме того, память выходного буфера должна иметь выходную пропускную способность равную V бит/с и входную пропускную способность равную KV бит/с, для того чтобы принять все К ячейки, прибывающие за один временной интервал. 3.5.2 КОММУТАЦИОННАЯ СИСТЕМА С ПЕРЕСТАНОВКОЙ И МАРШРУТИЗАЦИЕЙ С ОТКЛОНЕНИЕМРассмотрим N´N коммутационную систему с перестановкой (SN) с n=log2N каскадами, каждый из которых состоит из N/2 2´2 коммутационных элементов. На рисунки 3.15 представлена коммутационная система с перестановкой 8´8 [19,20].
Рисунок 3.15 - Коммутационная система с перестановкой 8´8 Коммутационные узлы на каждом каскаде отмечены сверху вниз двоичным числом в (n-1) бит. Верхний ввод/вывод узла отмечен 0, а нижний - 1. Ячейка будет направлена в вывод 0 (1) в каскаде i, если i наиболее значительный бит адреса ее назначения =0 (1). Взаимосвязь между 0 двумя, следующими друг за другом каскадами называется перестановкой. Вывод am узла X=(a1, a2...an-1) соединен со вводом а1 узла Y=(a2, а3......аn) следующего каскада. Связь между узлами X и Y обозначена <an, а1>. Канал от ввода к выводу, по которому трассируется ячейка определяется ее адресом источника S=sl...sn и адресом ее назначения D=d1...dn, что символически выражается так [19,20]:
Последовательность узлов на канале выражается двоичной цепью s2...sn, d1...dn-1, представленной (n-1) разрядным окном, сдвигающимся на один бит слева направо в каждом каскаде. Трассировку ячейки по SN можно обозначить парой (R,X), где R - текущая трассировка, а X - узел постоянного хранения ячейки. В первом каскаде ячейка находится в состоянии (dn...d1, s2...sn) Состояние передачи определяется алгоритмом самотрассировки так [19,20]:
Заметьте что в конце каждого каскада трассировочный бит удаляется. Наконец, из состояния.... ячейка будет коммутирована следующим 2´2 элементом по назначению. При конфликте в узле, только одна ячейка будет трассирована верно, а все остальные не попадут к нужным выходам. Отклонившаяся ячейка может начать трассировку вновь (с трассировочным ярлыком в исходном состоянии dn...d1) с того места, где произошло отклонение. Поэтому, если расширить SN систему так, чтобы она включала более n каскадов, то отклонившиеся ячейки могут достигнуть своего вывода на последующих каскадах. Т.к. некоторые ячейки достигнут своего вывода позже других на несколько каскадов, необходим мультиплексор для сбора ячеек, достигающих физических каналов одного и того же логического адреса на разных каскадах. В итоге, ячейка попадет по адресу своего назначения, при условии, что число L каскадов достаточно велико. Если она не находит своего вывода и на последнем из L каскадов, она считается потерянной. |
|