|
Рефератырусскому языку полиграфия хозяйство |
Дипломная работа: Программно-методический комплекс для обучения процессу создания компиляторовДипломная работа: Программно-методический комплекс для обучения процессу создания компиляторовМИНИСТЕРСТВО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИВОТКИНСКИЙ ФИЛИАЛ ИЖ Г Т УКафедра Организации вычислительных процессов и систем управления
К защите допустить “____”_________ 2003 г
Зав. кафедрой ___________ дипломный проект
ТЕМА:
РАСЧЕТНО - ПОЯСНИТЕЛЬНАЯ ЗАПИСКАВыполнил студент группы Д – 1061 _________ А.И. Кузнецов
Руководитель проекта ст. преподаватель _________
Консультант по профессор, д.т.н. _________ охране труда Консультант по эко- доцент, к.т.н. _________ номической части Председатель экс- ст. преподаватель _________ пертной комиссии
Воткинск 2003Определения В настоящем дипломном проекте применяются следующие термины с соответствующими определениями. Ассемблер - программа, которая переводит исходную программу, написанную на автокоде или на языке ассемблера (что, суть, одно и то же), в объектный (исполняемый) код. БНФ (Бэкуса нормальная форма) – грамматика, состоящая из конечного множества правил, определяющих в совокупности язык программирования. Выражение правила получения нового значения с помощью знаков операций и скобок, частным случаем выражения может быть просто одиночный элемент, т.е. константа или переменная. Идентификатор имя переменной, процедуры, функции, программы. Инструкция синтаксическая структура, содержащая ключевые, шумовые слова и конструкции. Бывают простые и структурированные. Простые инструкции не содержат в себе других вложенных инструкций (присваивание, GOTO). Структурированные инструкции могут содержать вложенные инструкции (IF <булево выражение> THEN <безусловный оператор> ELSE <оператор>). Компилятор системная программа, выполняющая преобразование программы, написанной на одном алгоритмическом языке, в программу на языке, близком к машинному, и в определенном смысле эквивалентную первой. Лексема единица программы, получающаяся в результате лексического анализа, например: for, i, 10, integer, + и т. п. Лексический анализ – выделение в исходной программе элементарных составляющих: идентификаторов, ограничителей, символов операторов, чисел, ключевых слов, шумовых слов, пробелов, комментариев и т. п. Литера любой символ, множество литер составляют лексему. Литерал численное или строковое значение, заданное один раз, и не изменяемое в течение программы. Метод операторного предшествования – восходящий метод грамматического разбора, основан на анализе пар последовательно расположенных операторов исходной программы и решении вопроса о том, какой из них должен выполняться первым. Нетерминальный символ – имя конструкции, определенной внутри грамматики. Рекурсивный спуск – нисходящий метод грамматического разбора, основан на том, что для каждого нетерминального символа, определенного в грамматике, существует отдельная процедура обработки. При этом в процессе своей работы она может вызывать подобные процедуры Семантика языка программирования - это смысл, который закладывается в каждую конструкцию языка. Семантический анализ - это проверка смысловой правильности конструкции. Например, если мы в выражении используем переменную, то она должна быть определена ранее по тексту программы, а из этого определения может быть получен ее тип. Исходя из типа переменной, можно говорит о допустимости операции с данной переменной. Семантический анализ – в нем обрабатываются структуры, распознанные синтаксическим анализатором, и начинает обретать очертания выполняемый код. Символьное имя – одно из имен, разрешенных в языке, не являющееся терминальным символом. Синтаксис языка программирования - это правила составления предложений языка из отдельных слов. Такими предложениями являются операции, операторы, определения функций и переменных. Особенностью синтаксиса является принцип вложенности (рекурсивность) правил построения предложений. Это значит, что элемент синтаксиса языка в своем определении прямо или косвенно в одной из его частей содержит сам себя. Например, в определении оператора цикла телом цикла является оператор, частным случаем которого является все тот же оператор цикла. Синтаксический анализ (грамматический разбор) – формирует синтаксическую единицу выражение, инструкцию, вызов подпрограммы, декларацию, которые далее обрабатываются семантическим анализатором. Пример структуры: FOR <выражение> TO int DO <body>. Синтаксический разбор – процесс получения дерева синтаксического разбора на основе заданной грамматики. Сканер (лексический анализатор) – программа распознавания лексем. Спецификатор порядковый номер в таблице, куда занесена лексема. Терминальный символ – конечный неделимый элемент конструкции языка, является зарезервированным словом (например READ, (, +). Транслятор это системная программа, выполняющая преобразование программы, написанной на одном алгоритмическом языке, в программу на другом алгоритмическом языке в определенном смысле эквивалентную первой. Содержание Введение................................................................................................... 19 1 Анализ предметной области................................................................ 20 1.1 Компиляторы........................................................................... 20 1.2 Логическая структура компилятора..................................... 21 1.3 Лексический анализ. Сканер.................................................... 24 1.4 Синтаксический и семантический анализ.............................. 28 1.5 Грамматики............................................................................. 31 1.6 Формирование промежуточного кода................................... 34 Метод четверок..................................................................... 36 1.7 Обоснование создания учебного комплекса............................. 37 1.8 Обзор существующих разработок.......................................... 38 1.9 Обоснование разработки........................................................ 39 2 Создание учебной разработки............................................................. 42 2.1 Краткое описание учебного компилятора............................. 42 2.2 Описание учебного языка......................................................... 43 2.3 Лексический анализатор LEXAN............................................ 46 2.3.1 Таблица терминальных символов.............................. 47 2.3.2 Таблица символических имен..................................... 48 2.3.3 Таблица литералов...................................................... 49 2.3.4 Работа сканера............................................................. 50 2.3.5 Структура листинга..................................................... 50 2.3.6 Структура выходного файла...................................... 50 2.3.7 Примерное задание для студента............................... 52 2.3.8 Описание работы лексического анализатора............. 53 2.4 Синтаксический анализатор SinAn........................................ 56 2.4.1 Таблица переходов...................................................... 56 2.4.2 Правила работы с таблицей переходов...................... 60 2.4.3 Правила таблицы переходов для написания программы 62 2.4.4 Формируемая таблица переходов. Правила заполнения 65 2.4.5 Правила заполнения формируемой таблицы переходов 66 2.4.6 Построение деревьев................................................... 81 2.4.7 Семантический анализ................................................. 83 2.5 Формирование промежуточного кода................................... 85 Циклы.................................................................................... 85 3 Определение трудоемкости по стадиям разработки........................... 89 3.1 Методика расчета.................................................................. 89 3.2 Определение затрат на выполнение проекта по стадиям разработки 92 3.3 Расчет затрат на выполнение проекта по этапам.............. 94 4 Рекомендации по охране труда при работе с учебным комплексом. 95 Заключение.............................................................................................. 97 Список использованных источников...................................................... 98 Приложения............................................................................................. 99 Введение Каждый преподаватель вправе преподносить материал и обучать студентов по любой из дисциплин так, как он считает нужным. Преподаватель желает, чтобы знания по преподаваемым наукам лучше усваивались студентами. Часто материал не усваивается из-за того, что нет его наглядного представления, нет материалов, будь то программных или выполненных в виде плакатов, стендов, способствующих более глубокому пониманию. Для того чтобы создать демонстрационный вспомогательный материал следует наработать необходимую базу. Что занимает много времени и требует определенных усилий и больших временных затрат. В результате могут быть получены плакаты, методические пособия, программные средства (тестовые, обучающие) и др. Некоторые из них можно применять и в отсутствии преподавателя для самообучения, для контроля знаний и т. п. Для проверки знаний часто используют тестовые системы, в которых проверка знаний происходит в интерактивном режиме. Некоторые из них лишь выдают какой-то общий результат, другие определяют, где и на каком этапе возникла ошибка, и сообщают об этом пользователям (используется в компиляторах). 1 Анализ предметной области 1.1 КомпиляторыТранслятор - это программа, которая переводит исходную программу в эквивалентную ей объектную программу. Если объектный язык представляет собой автокод или некоторый машинный язык, то транслятор называется компилятором. Автокод очень близок к машинному языку; большинство команд автокода - точное символическое представление команд машины. Ассемблер - это программа, которая переводит исходную программу, написанную на автокоде или на языке ассемблера (что, суть, одно и то же), в объектный (исполняемый) код. Компиляторы пишутся как на автокоде, так и на языках высокого уровня. Кроме того, существуют и специальные языки конструирования компиляторов - компиляторы компиляторов. Компилятор компиляторов (КК) – система, позволяющая генерировать компиляторы; на входе системы - множество грамматик, а на выходе, в идеальном случае, - программа. Иногда под КК понимают язык программирования, в котором исходная программа - это описание компилятора некоторого языка, а объектная программа - сам компилятор для этого языка. Исходная программа КК - это просто формализм, служащий для описания компиляторов, содержащий, явно или неявно, описание лексического и синтаксического анализаторов, генератора кодов и других частей создаваемого компилятора. Обычно в КК используется реализация схемы т.н. синтаксически управляемого перевода. Кроме того, некоторые из них представляют собой специальные языки высокого уровня, на которых удобно описывать алгоритмы, используемые при создании компиляторов. 1.2 Логическая структура компилятораНа рисунке 1 представлена структурная схема компилятора.
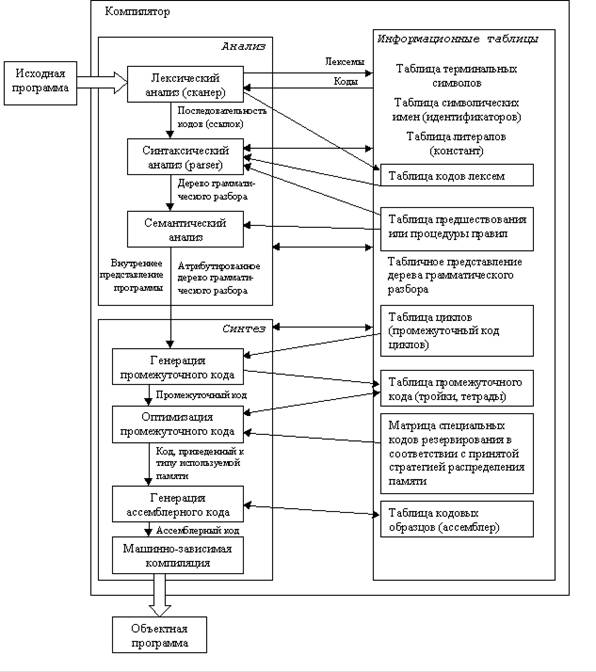
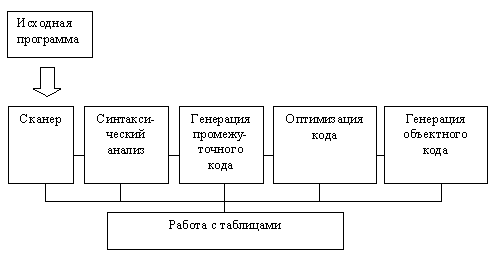
Рисунок 1 – Схема компилятора Исходная программа – текст программы на языке высокого уровня (например Паскаль), который должен быть переведен в машинный код. Информационные таблицы - самостоятельные структуры, заранее заполненные (таблица терминальных символов), а также заполняющиеся в ходе лексического анализа и дополняющиеся во время работы. Лексический анализатор выполняет распознавание лексем языка и замену их соответствующими кодами. Под лексемами понимаются элементарные единицы, входящие в структуру предложения языка, такие как ключевые слова, константы, имена и т.п. Правильность задания структуры предложения языка на фазе лексического анализа не выполняется. Результатом является поток лексем (кодов – ссылок на таблицы), эквивалентный исходному тексту. Синтаксический анализатор необходим для того, чтобы выяснить, удовлетворяют ли предложения, из которых состоит исходная программа, правилам грамматики этого языка. Семантический анализ. На этом этапе осуществляется контроль типа и вида всех идентификаторов и других операндов. Генерация промежуточного кода. Происходит преобразование исходной программы в промежуточную (например, польскую) форму записи. Оптимизация промежуточного кода выделение общих подвыражений и вычисление константных подвыражений. Фаза оптимизации предназначена для уменьшения избыточности программы по затратам времени и памяти. В зависимости от критериев проектирования транслятора данная фаза обработки программы может исключаться из цикла обработки программы. Распределение памяти. На этом этапе выделяются конкретные адреса пользователя под переменные, которые генерируются компилятором. Генератор объектного (ассемблерного) кода – выполняет подстановку кодовых образцов на выходном языке, соответствующих промежуточным кодам программы. Генератору кода могут не требоваться шаблоны, он весь может быть реализован в процедурном виде. Машинно-зависимая компиляция. Зависит от того, какие используются регистры. Работа этой процедуры зависит от соглашений, принятых для исполняемой части программы. Например, выделяется базовый регистр для текущей активной записи в стеке. На всех этих этапах происходит работа с различного рода таблицами. В частности, для каждого блока (если таковые существуют в языке) идентификаторы, описанные внутри, запоминаются вместе со своими атрибутами. Условно все эти этапы можно изобразить следующим образом:
Рисунок 2 – Работа с таблицами Очевидна зависимость структуры компилятора от структуры ЭВМ, точнее, от имеющейся производительности системы. Например, при малой памяти увеличивается количество проходов компиляции (т.н. многопроходные компиляторы), а при наличии памяти большого объема можно все этапы компиляции произвести за один проход (и тогда мы имеем дело с однопроходным компилятором). Далее мы рассмотрим некоторые из этих составных частей процесса компиляции. 1.3 Лексический анализ. СканерЛексический анализатор представляет собой модуль разбора текста программы. Разбор происходит в зависимости от имеющихся у него в памяти терминальных символов и правилами определения типов данных. Каждый язык имеет свои ограничения по типам данных, допущения и особенности создания (строения) конструкций, применению операторов и т.п. При работе сканера используются три таблицы: таблица терминальных символов, таблица символических имен и таблица литералов – это заполняемые таблицы. Таблица терминальных символов хранит все ключевые слова и специальные символы используемые в языке, а также коды, соответствующие каждому символу. Таблица символических имен заполняется в процессе разбора текста программы и хранит в себе имена идентификаторов (символических имен). Таблица литералов также заполняется в процессе разбора программы и хранит в себе литералы: численные и строковые значения, с указанием типов данных и относительных адресов. Распределение по таблицам происходит следующим образом. Сканер в процессе анализа текста программы выделяет один из элементов текста и сравнивает с каждым терминальным символом. Если такой символ найден, то в выходной код передаются код таблицы и спецификатор (номер строки в таблице). В случае если этот элемент не является терминальным символом проверяется, является ли он идентификатором (первый символ обычно буква, остальные могут быть либо буквой, либо цифрой), если такой определен, то данный элемент заносится в таблицу символических имен, а к выходному коду добавляется пара численных значений: номер таблицы и спецификатор найденного элемента. В случае если такой элемент в таблице уже имеется, то в выходной код заносится номер таблицы и его спецификатор. В таблицу литералов заносят численные, строковые и иные определенные языком значения. При этом распознается тип значения и тут же заполняется относительная таблица адресов. Выходной код, сформированный сканером, передается на следующую стадию обработки синтаксический анализ. Таким образом, алгоритм работы простейшего сканера можно описать так: · просматривается входной поток символов программы на исходном языке до обнаружения очередного символа, ограничивающего лексему; · для выбранной части входного потока выполняется функция распознавания лексемы; · при успешном распознавании информация о выделенной лексеме заносится в таблицу лексем, и алгоритм возвращается к первому этапу; · при неуспешном распознавании выдается сообщение об ошибке, а дальнейшие действия зависят от реализации сканера - либо его выполнение прекращается, либо делается попытка распознать следующую лексему (идет возврат к первому этапу алгоритма). Работа программы-сканера продолжается до тех пор, пока не будут просмотрены все символы программы на исходном языке из входного потока. Таблица терминальных символов в простейшем случае может иметь следующий вид как показано в таблице 1. Таблица 1 – Таблица терминальных символов
Продолжение таблицы 1
Сначала заполняется таблица лексем (терминальных символов), затем начинается считывание и обработка входного текста программы пользователя. При работе сканера происходит заполнение таблиц символических имен и литералов. Данные таблицы могут выглядеть следующим образом: Таблица 2 – Таблица символических имен
Таблица 3 – Таблица литералов
Результатом работы сканера является последовательность кодов лексем. Каждый код лексемы обычно представляется кодом таблицы и спецификатором (порядковый номер в таблице, куда занесена лексема). Это позволяет избежать дополнительного поиска по таблицам на следующих этапах трансляции. Например в результате обработки сканером следующего предложения языка Паскаль FOR I:=1 TO 100 DO Y:=X1 будет получена строка: <1,06><2,1><1,14><3,1><1,07><3,2><1,08><2,2><1,14><2,3>, где в угловых скобках пара чисел задает код таблицы и спецификатор. Можно оформить и в виде таблицы. Таблица 4 – Таблица выходных символов
Функционально в сканере могут быть выделены следующие модули[4]: 1) выделение из входной строки очередного слова; 2) поиск в таблицах лексем и определение кода лексемы; 3) формирование и вывод выходной строки. Для модуля выделения слова важна информация о том, какие символы могут быть признаками начала или конца слова. Например, в языке Паскаль ключевые слова отделяются от других элементов предложения пробелами. Сложнее обстоит дело с выделением идентификаторов и чисел, поскольку разделителем для них может служить любой другой символ, не входящий по определению в идентификатор или число. При заполнении таблиц выполняется проверка на наличие в ней элемента, совпадающего с выделенным идентификатором или константой, и при совпадении занесение в таблицу не выполняется. В задачи последнего модуля входит занесение в выходную строку кодов лексем. В дополнение к своей основной функции, распознаванию лексем, сканер обычно также выполняет чтение строк исходной программы и, возможно, печать листинга исходной программы. Комментарии игнорируются сканером, за исключением того случая, когда они должны быть напечатаны и, таким образом, эффективно удаляются из исходной программы до начала процесса грамматического разбора. Следующей стадией анализа является синтаксический разбор. Лексический и синтаксический анализаторы взаимодействуют между собой. Существует два основных способа взаимодействия: 1) реализуется на основе прямого лексического анализа. От синтаксического анализатора поступает запрос «дать лексему» и указывается тип лексемы; 2) непрямой лексический анализ. Синтаксический анализатор выдает запрос «дать лексему», тип лексемы не указывается. Нет решающего блока, считаем, что работает группа параллельных автоматов. 1.4 Синтаксический и семантический анализСинтаксический анализ - это процесс, в котором исследуется цепочка лексем и устанавливается, удовлетворяет ли она структурным условиям, явно сформулированным в определении синтаксиса языка. Это – самая сложная часть компилятора. Синтаксический анализатор расчленяет исходную программу на составные части, формирует ее внутреннее представление, заносит информацию в таблицу символов и другие таблицы. При этом производится полный синтаксический и, по возможности, семантический контроль программы. Фактически, это - синтаксически управляемая программа. При этом обычно стремятся отделить синтаксис от семантики насколько это возможно - когда синтаксический анализатор распознает конструкцию исходного языка, он вызывает семантическую процедуру, которая контролирует эту конструкцию, заносит информацию куда надо, проверяет на дублирование описания переменных, проверяет соответствие типов и т.п. Процесс синтаксического анализа может рассматриваться как построение дерева грамматического разбора для транслируемых предложений. Грамматики могут использоваться как для порождения так и для распознавания предложений языка. Порождение начинается с начального понятия (или аксиомы грамматики). При распознавании с помощью грамматических правил порождается предложение, которое затем сравнивается с входной строкой. При этом применение правил подстановки для порождения очередного символа предложения зависит от результатов сравнения предыдущих символов с соответствующими символами входной строки. Результат анализа исходного предложения в терминах грамматических конструкций удобно представлять в виде дерева. Такие деревья обычно называются деревьями грамматического разбора или синтаксическими деревьями. На рисунке 3 изображено дерево грамматического разбора для предложения READ (VALUE).
Рисунок 3 – Дерево грамматического разбора Методы грамматического разбора разбиваются на два больших класса восходящие и нисходящие в соответствии с порядком построения дерева грамматического разбора. Нисходящие (методы сверху-вниз) начинаются с аксиомы грамматики, с корня дерева и пытаются так его наращивать, чтобы последующие узлы дерева соответствовали синтаксису анализируемого выражения. Восходящие (методы снизу-вверх) начинают с элементов предложения (с "листьев") и отыскивают в грамматике какому понятию они соответствуют, т.е. определяют родительскую вершину для этих элементов, и т.д. пока не приходят к корню дерева (аксиоме грамматики). В современных компиляторах применяются как нисходящие, так и восходящие методы. Достоинством восходящего метода является его несомненная простота, а также высокая скорость выполнения (не тратится время на поиск правила редукции). Однако все эти достоинства напрочь меркнут перед главным недостатком данного метода. Дело в том, что здесь практически отсутствует какая бы то ни была диагностика (и тем более - локализация) ошибок. Во вторых, некоторые ошибки в исходном выражении не диагностируются вовсе. Например, выражения, в которых встречаются идущие подряд скобки “(” и “)”. Поэтому при дальнейшем рассмотрении будет рассматриваться нисходящий разбор, как наиболее пригодный метод при ручном написании компилятора [4]. Кроме этого, алгоритмы синтаксического (грамматического) разбора (контроля) делят на синтаксически-ориентированные и синтаксически-неориентированные. Синтаксически-ориентированные алгоритмы являются универсальными для некоторого семейства языков и переход к распознаванию предложений другого языка выполняется путем смены грамматики, т.е. грамматика выполняет роль некоей "программы" распознавания предложений языка. Главным достоинством этого класса алгоритмов является их универсальность, а недостатком - наличие избыточности вследствие ориентации на семейство языков. Синтаксически-неоpиентиpованные алгоритмы отличаются тем, что порядок действий в них определяется правилами грамматики данного конкретного языка. Достоинством этого класса алгоритмов является отсутствие избыточности, а недостатком - невозможность перенастройки на распознавание предложений другого языка. В дальнейшем мы будем работать с синтаксически-неориентированными алгоритмами, т.к. будем работать лишь с одним языком – учебный язык на основе языка Паскаль. 1.5 ГрамматикиГрамматика языка программирования является формальным описанием его синтаксиса или формы, в которой записаны отдельные предложения программы или вся программа. Грамматика не описывает семантику или значения различных предложений. Информация о семантике содержится в программах генерации объектного кода. В качестве иллюстрации разницы между синтаксисом и семантикой рассмотрим два предложения: I:=J+K и I:=X+Y где Х и Y являются действительными переменными, a I, J, К — целыми переменными. Эти два предложения имеют одинаковый синтаксис. Оба являются операторами присваивания, в которых присваиваемое значение определяется выражением, состоящим из двух имен переменных, разделенных оператором сложения. Однако семантика этих двух предложений совершенно различна. Первое предложение говорит о том, что переменные в выражении должны быть сложены с использованием целых арифметических операций, а результат сложения должен быть присвоен переменной I. Второе предложение задает сложение с плавающей точкой, результат которого должен быть преобразован в целое число перед присваиванием. Очевидно, эти два предложения будут скомпилированы в различные последовательности машинных команд, хотя их грамматическое описание одинаково. Различия между ними проявятся на этапе генерации объектного кода. На рисунке 4 показаны БНФ грамматики, используемые в дипломном проекте. Подчеркнутые волнистой линией элементы могут опускаться (не использоваться). 1. <prog> ::= PROGRAM <prog-name> VAR <dec-list> BEGIN <stmt-list> END. 2. <prog-name> ::= id ; 3. <dec-list> ::= <dec> { ; <dec> } ; 4. <dec> ::= <id-list> : <type> 5. <type> ::= INTEGER | REAL | STRING 6. <id-list> ::= id { , id } 7. <stmt-list> ::= <stmt> { ; <stmt> } ; 8. <stmt> ::= <assign> | <for> | <read> | <write> | <while> | <repeat> | <if> 9. <assign> ::= id := <exp> 10. <exp> ::= – <term> + <term> 11. <term> ::= <factor> DIV <factor> 12. <factor> ::= id | int | real | <text-val> | (<exp>) 13. <read> ::= READ ( <id-list> ) 14. <write> ::= WRITE ( <value> { , <value>} ) 15. <for> ::= FOR <index-exp> DO <body> 16. <index-exp> ::= id := <exp> TO|DOWNTO <exp> 17. <body> ::= <stmt> | BEGIN <stmt-list> END 18. <value> ::= <id-list> | <text-val> 19. <text-val> ::= ′ <text> ′ 20. <text> ::= string 21. <if> ::= IF <сравнение> THEN <body> ELSE <body> 22. <сравнение>::= <factor> <условие> <factor> 23. <условие> ::= > | < | = | >= | <= | <> 24. <while> ::= WHILE <сравнение> DO <body> 25. <repeat> ::= REPEAT <body> UNTIL <сравнение> Рисунок 4 – Упрощенная грамматика языка Паскаль Существует несколько различных форм записи грамматик, среди которых мы рассмотрим форму Бекуса—Наура (БНФ). БНФ не самое мощное из известных средств описания синтаксиса. Однако эта форма достаточно проста, широко используется и предоставляет достаточные для большинства приложений средства. На рис.4 изображена одна из возможных грамматик БНФ. Грамматика БНФ состоит из множества правил вывода, каждое из которых определяет синтаксис некоторой конструкции языка программирования. Рассмотрим, например, правило 13 на рис. 4: <read> ::= READ ( <id-list> ) Это определение синтаксиса предложения READ языка Паскаль, обозначенное в грамматике как <read>. Символ ::= можно читать как «является по определению». С левой стороны от этого символа находится определяемая конструкция языка (в нашем случае— <read>), а с правой—описание синтаксиса этой конструкции. Строки символов, заключенные в угловые скобки < и >, называются нетерминальными символами (т. е. являются именами конструкций, определенными внутри грамматики). То, что не заключено в угловые скобки, называется терминальными символами грамматики (лексемами). В этом правиле вывода нетерминальными символами являются <read> и <id—list>. Терминальными символами являются лексемы READ, (, ). Таким образом, это правило определяет, что конструкция <read> состоит из лексемы READ, за которой следует лексема (, за ней следует конструкция языка, называемая <id—list>, за которой следует лексема ). Пробелы при описании грамматических правил не существенны и вставляются только для наглядности. Для распознавания нетерминального символа <read> необходимо чтобы было определение для нетерминального символа <id-list>. Это определение дается правилом 6 на рис. 4: <id-list> ::= id { , id } Эта нотация, означает, что конструкция, заключенная в фигурные скобки, может быть либо опущена, либо повторяться один или более число раз. Таким образом, правило 6 определяет нетерминальный символ <id-list> как состоящий из единственной лексемы id или же из произвольного числа следующих друг за другом лексем id, разделенных запятой. В соответствии с этим новым определением процедура, соответствующая нетерминальному символу <id-list>, сначала ищет лексему id, а затем продолжает сканировать входной текст до тех пор, пока следующая пара лексем не совпадет с запятой и id. Такая запись устраняет проблему левой рекурсии. 1.6 Формирование промежуточного кодаВозможны различные формы внутреннего представления синтаксических конструкций исходной программы в компиляторе. Дерево грамматического разбора оказывается неудобным в работе при работе при генерации и оптимизации объектного кода. Поэтому перед оптимизацией и непосредственно генерацией объектного кода внутреннее представление программы преобразуется в одну из соответствующих форм записи. Примерами таких форм записи являются: - обратная польская запись операций; - тетрады операций; - триады операций; - собственно команды ассемблера. Обратная польская запись - это постфиксная запись операций. Преимуществом ее является то, что все операции записываются непосредственно в порядке их выполнения. Она чрезвычайно эффективна в тех случаях, когда для вычислений используется стек. Тетрады представляют собой запись операций в форме из четырех составляющих: <операция>(<операнд1>,<операнд2>,<результат>). Тетрады используются редко, так как требуют больше памяти для своего представления, чем триады, не отражают взаимосвязи операций и, кроме того, плохо отображаются в команды ассемблера и машинные коды, так как в наборах команд большинства современных машин не встречаются операции с тремя операндами. Триады представляют собой запись операций в форме из трех составляющих: <операция>(<операнд1>,<операнд2>), при этом один или оба операнда могут быть ссылками на другую триаду в том случае, если в качестве операнда данной триады выступает результат выполнения другой триады. Поэтому триады при записи последовательно номеруют для удобства указания ссылок одних триад на другие. Например, выражение A := B*C + D - B*10, записанное в виде триад будет иметь вид: 1) * ( B, C ) 2) + ( ^1, D ) 3) * ( B, 10 ) 4) - ( ^2, ^3 ) 5) := ( A, ^4 ) Здесь операции обозначены соответствующим знаком (при этом присвоение также является операцией), а знак ^ означает ссылку операнда одной триады на результат другой. Команды ассемблера удобны тем, что при их использовании внутреннее представление программы полностью соответствует объектному коду и сложные преобразования не требуются. Однако использование команд ассемблера требует дополнительных структур для отображения их взаимосвязи. Кроме того, внутреннее представление программы получается зависимым от результирующего кода, а это значит, что при ориентации компилятора на другой результирующий код потребуется перестраивать как само внутреннее представление программы, так и методы его обработки в алгоритмах оптимизации (при использовании триад или тетрад этого не требуется). Для построения внутреннего представления объектного кода (в дальнейшем - просто кода) по дереву вывода может использоваться простейшая рекурсивная процедура. Эта процедура прежде всего должна определить тип узла дерева - он соответствует типу операции, символ которой находится в листе дерева для текущего узла. Этот лист является средним листом узла дерева для бинарных операций и крайним левым листом - для унарных операций. После определения типа процедура строит код для узла дерева в соответствии с типом операции. Если все узлы следующего уровня для текущего узла есть листья дерева, то в код включаются операнды, соответствующие этим листьям, и получившийся код становится результатом выполнения процедуры. Иначе процедура должна рекурсивно вызвать сама себя для генерации кода нижележащих узлов дерева и результат выполнения включить в свой порожденный код. Поэтому для построения внутреннего представления объектного кода по дереву вывода в первую очередь необходимо разработать формы представления объектного кода для четырех случаев, соответствующих видам текущего узла дерева вывода: оба нижележащих узла дерева - листья (терминальные символы грамматики); |
|